
HTTP to HTTP with bash, curl and jq
Mapping an interface to another one and chaining the dots altogether are systematic needs in data processing. We end up writing loads of lines of code just to map and transfer these data.
Hopefully it becomes a fairly easy goal to achieve with a handful combination of curl, jq and bash operators.
§tl;dr
This blog post explains the principles of data pipelining over HTTP with only a few lines of bash scripting.
jq, curl and bash are at the heart of our data transforms requirements.
§Breakdown of the exercise
I have been doing a fair amount of data processing in the context of the Editorial algorithms BBC project, either to prototype distributed units or to isolate a chunk of data for debugging purposes.
In any case, I have never been able to simply pipe data into another API straight away. Processing was always involved. To filter out objects. To generate new metadata on the fly. To fit into a particular structure of data.
A recurring pattern of data pipelining is the following: (std)in -> data processing -> (std)out. From HTTP to disk, from disk to HTTP or even from HTTP to HTTP.
We will deep dive in each of these three steps to cover a day to day spectrum of data transforms.
Ah! And why not involving a programming language such as Ruby, Go or JavaScript? Because we can do it by sticking to the basics: bash. Best complementary programming language ever.

§Fetching some data
At this stage, we assume we only want to collect data from a remote HTTP API. Although only a subset of the response might be of our interest.
Best is to have the jq manual open in a different tab to get more familiar with it along the read.
§Filtering on a single value
This is the simplest need: only one field of the response has to be piped out.
Let’s take this fictional JSON response object:
1 | |
We might want to fetch the value of the textBody field like this:
1 | |
§Mapping values
Sometimes we need to alter the response object in order to fit into our data processing unit. This is useful if you want to combine fields, prefix or nullify some of them.
Let’s take the following fictional JSON response object:
1 | |
We would like to flatten the response into a simpler object, to combine the first and last name, to normalise the Twitter handle into its own field and to make the date compatible with the JavaScript Date object.
Again, jq is super powerful to take in account our various edge cases:
1 | |
jq’s -f flag enables to write our jq script into a separate file. Which I think is good for readability and reusability purposes:
1 | |
A few explanations here:
-X GET -G: forcescurlto recognise each of the-dparameters asGETquery string values (handy for programmatic and readable URL construction) — otherwise it would imply to send the request asPOST;jqparenthesis (()) wrap a series of operations into a result (string, number, array, object etc.);jq’sselectoutputs a result only if the assertion result is positive;jq’s//operator is an or statement:(something) // nullhas to be understood as something which might return a value or return a null value.
§Plucking one item from a collection
You might want to access a specific resource within a collection based on a known parameter.
For example, we would like to fetch the identifier of a record which name is example.com:
1 | |
The idea is to iterate over the results and return the content of the id field only if the name field value matches example.com:
1 | |
jq’s--argis a great way to inject env variable (or any other named value really) into the jq script (think reusability);jq’semptyvalue is special in a sense it is filtered out from an array. Because we flatten the array with[], we end up returning one or none value.

§Data processing
We do not necessarily want to pipe our filtered data straight away into another API. We might have to enrich them or to produce brand new metadata beforehand.
This second section will focus on processing data on the fly from a given source. Our examples do relate to text content (including JSON) but they apply to any software able to do streaming processing.
§Standard input
The easiest processing we can do is to provide a single blob of metadata to a software via stdin.
The following example denotes our intention to pipe a URL to a topic extractor backed by DBpedia:
1 | |
- topic extraction is performed by DBpedia Spotlight (and is sometimes not accurate at all);
jq’s-Roption prevents jq to parsestdinas a JSON input;jq’s@textis a special filter to output as… text, and not JSON (see Format strings and escaping;curl’s@-means read file from stdin — combined with-X GET -G, this is a way to build a query string from stdin.
A more hardcoded version of the aforementioned command would be:
1 | |
We now have acquired a richer representation of our input data.
We will do something more sophisticated with these data in the third section of this blog post.
§Line by line
This is definitely the most scalable way to process large files or to process data as we gather them from a remote source.
It enables you to get results without having to wait an entire dataset to be downloaded — which is handy to entertain your CPU whilst you saturate your downstream network bandwidth.
The following example turns email addresses into an md5 hash. This hash can be appended to a gravatar URL to obfuscate email addresses while turning them into illustrational materials:
1 | |
§Assembling a JSON payload
bash does not provide any secure way to manipulate JSON. We can concatenate strings and make JSON-ish strings… but we should not really: we want to be able to deal with character encoding and character escaping issues.
It happens than jq is actually a pretty neat candidate to build JSON payloads from scratch:
1 | |
jq’s-noption avoids to wait for stdin data — this is the trick to build JSON objects without parsing any input.
The JSON object is solely built from a jq template into which we inject jq variables (remember, --arg).
The aforementioned example is extracted from an cron job I use to update my SSL certificates (yay Let’s Encrypt!) via the HTTP API of my hosting service provider.
We can then reuse the previous result in another call:

§Piping into another API
Now we have fetched data and transformed them into something we can use and reuse, it is time to move them to another location without hitting the disk.
In this third section, we should be able to post any kind of JSON data to meet the expectations of a remote API.
§Standard input to curl
We are going to build up over the standard input data processing example from the section two.
Except this time, we are going to continue and wrap the collected data. The newly assembled JSON payload will be the body of an HTTP POST request:
1 | |
- because
@is a special character forjq, we escape it using double quotes — hence the.Resources[]."@URI"instead of.Resources[].@URI; jq’suniquefilter removes duplicates entries within an array;-d @-is really handy again as it gives us the ability to format our JSON payload at will.
§Programmatic GitHub Gist
A colleague of mine recently reported an issue with one of our metadata producer. I needed to isolate a piece of data but I wanted two things:
- to make the data available from the command line, outside of the system producing them;
- to enable me to send the problematic payload as much as I wanted until we could diagnose the origin of the issue.
So let’s finish with an example of how to dump some JSON data into a private GitHub Gist.
You can find additional materials under the Create a gist section of GitHub API reference.
You need to create/use a Personal access token to publish a gist without revealing your password. Head towards your GitHub personal settings to do so.
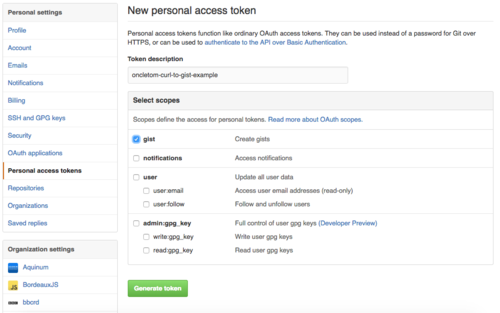
We will reuse the token as the GH_OAUTH_TOKEN environment variable in the following example:
1 | |
jq’stostringfilter formats a JSON object as a embeddable string — wrapping JSON into JSON!
In this example, we formatted the data twice:
- first to build a JSON structure we are interested in;
- then we structure it in a way the GitHub API can understand.
It illustrates various ways of combining environment variables and stdin processing.

§Conclusion
I kind of like this ability to make powerful processing with basic bricks. Bricks we then make evolve into a more complex structure to cope with our needs.
This approach is good to prototype. To prototype datasets. To prototype a data flow between application prototypes. To reproduce faulty data scenarios.
This is also great if you need to interface various APIs from a shell access only.
And finally, there is no hype involved: just long lasting and solid bash/fish/zsh/wtfsh programming knowledge.