|
💡
|
Vous êtes en train de lire le Chapitre 2 du livre “Node.js”, écrit par Thomas Parisot et publié aux Éditions Eyrolles. L’ouvrage vous plaît ? Achetez-le sur Amazon.fr ou en librairie. Donnez quelques euros pour contribuer à sa gratuité en ligne. |
Installons Node et l’outillage de développement qui nous correspond le mieux, peu importe notre niveau de familiarité avec le développement logiciel.
-
Installer Node.js sur notre ordinateur
-
Choisir un éditeur de code pour écrire nos programmes
-
Déterminer quand migrer vers une nouvelle version de Node.js
Certains systèmes d’exploitation embarquent l’environnement d’exécution Node, tandis que d’autres ne le font pas, ou alors dans une version trop ancienne. Idéalement, nous voudrions pouvoir installer la version de Node de notre choix.
Les éditeurs de code nous facilitent la vie en rendant le code lisible en ajoutant de la couleur et des repères visuels. Ces logiciels nous invitent à piocher dans leur bibliothèque d’extensions pour en faire un outil qui nous ressemble.
|
💬
|
Remarque Versions de Node et npm
Le contenu de ce chapitre utilise les versions Node v10 et npm v6. Ce sont les versions stables recommandées en 2022. |
Il n’est pas nécessaire d’avoir suivi des études d’informatique pour vouloir s’essayer à la programmation. Cela n’implique pas non plus d’en faire son métier.
Que l’on se qualifie de débutant·e, confirmé·e ou expert·e, il y a un petit rituel auquel on coupera difficilement :
-
installer Node.js pour voir le résultat de nos programmes écrits en JavaScript ;
-
installer un éditeur de code pour écrire nos programmes JavaScript plus confortablement.
Si l’idée est de jouer rapidement avec du code, sans rien installer et avec le premier ordinateur qui vous passe sous la main, je vous invite à aller directement à la section “Sans installation, dans un navigateur web” ci-après.
Les sections qui suivent vont vous aider à créer un environnement Node à jour sur votre ordinateur. Ce contenu s’applique également à un serveur destiné à héberger vos applications.
3. Installer Node.js
Il y a plusieurs manières d’installer Node sur une machine. Elles sont toutes correctes. Certaines sont plus adaptées que d’autres, selon votre aisance avec un terminal et selon le besoin de jongler rapidement entre différentes versions de Node.
-
Si vous vous êtes déjà servi d’un terminal : je recommande d’utiliser nvm.
-
Si vous ne vous êtes jamais servi d’un terminal : il est plus simple d’utiliser un installeur depuis le site officiel de Node.
-
Si vous souhaitez maîtriser les options d’installation : il serait logique de compiler depuis les sources et/ou d’utiliser Docker.
-
Si rien de tout ça ne vous parle : des services en ligne rendent Node accessible depuis un simple navigateur web.
|
💬
|
Question Pourquoi utiliser un installeur ?
Les installeurs facilitent l’installation de Node, en quelques clics et sans toucher à un terminal. Si vous utilisez un installeur correspondant à une version plus récente de Node, c’est celle-ci qui sera utilisée dans tous vos projets. C’est la solution la plus simple pour installer Node. |
3.1. Sans installation, dans un navigateur web
Il est facile de s’essayer à Node avec un navigateur web moderne comme Firefox, Edge ou Chrome. Des services en ligne combinent un éditeur de texte et un environnement d’exécution Node à distance.
Nous brosserons le portrait de trois services qui diffèrent par leurs fonctionnalités et leur rapidité de prise en main :_RunKit, Codenvy et Cloud9.
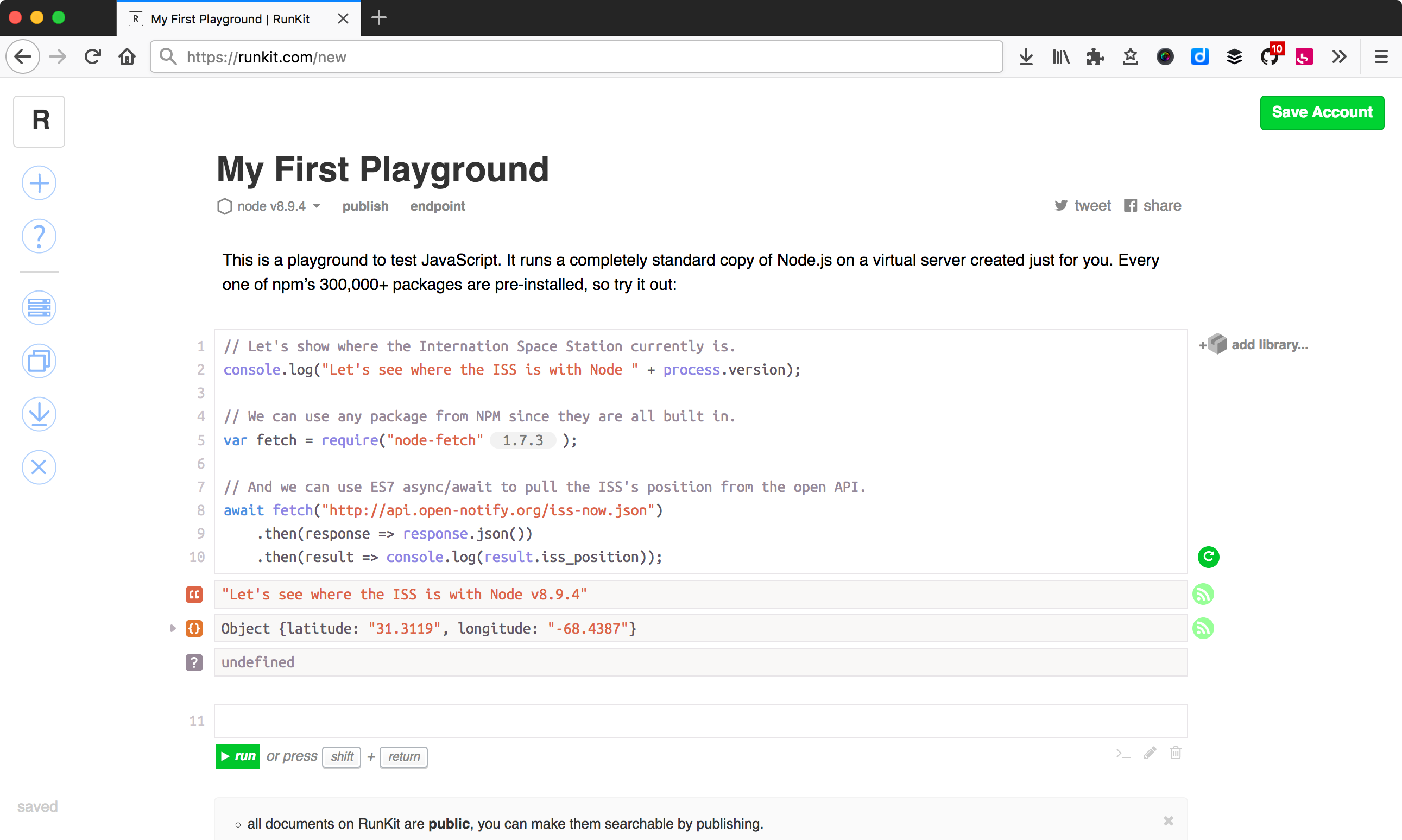
RunKit (runkit.com) est de loin le service le plus simple. Il s’articule autour d’un concept de bac à sable ; notre code ne sera pas plus long qu’un fichier. Pour créer un nouveau bac à sable, il suffit de se rendre sur runkit.com/new.
Codenvy (codenvy.io) est un service basé sur le logiciel open source Eclipse et édité par la compagnie Red Hat. L’interface est organisée exactement comme un des éditeurs de texte abordé plus loin dans ce chapitre.
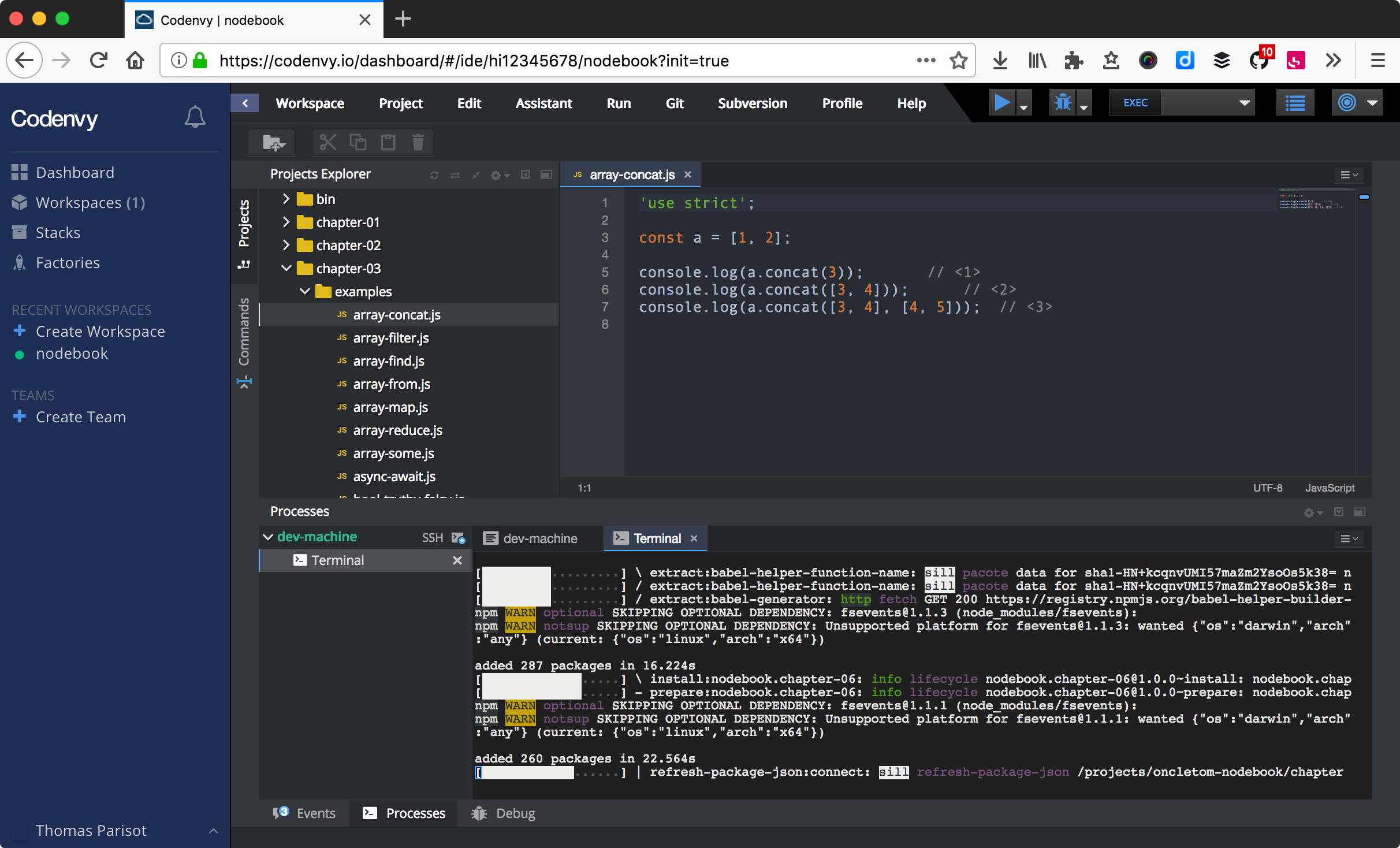
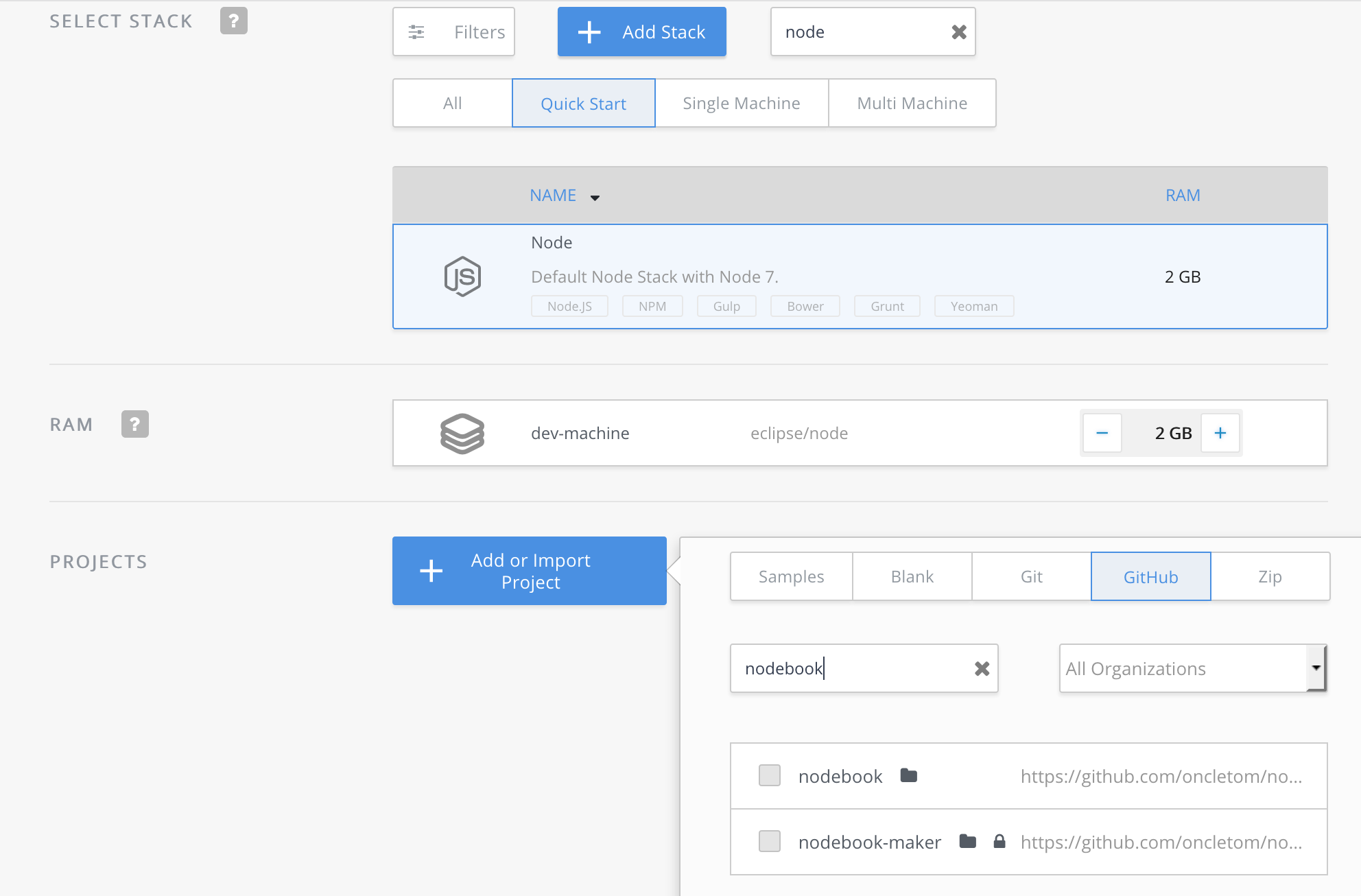
Le processus de création de projet est relativement intuitif et il est très facile d’importer du code hébergé en ligne, sur GitHub notamment. La configuration minimale d’un projet est gratuite tandis que les fonctionnalités avancées et le travail en équipe sont payantes.
Enfin, Cloud9 (c9.io) est un service propriétaire édité par la compagnie Amazon Web Services (AWS, aws.amazon.com). Il intègre des fonctionnalités similaires à celles de Codenvy (éditeur en ligne, configuration de machine) et s’intègre de manière poussée avec les autres services d’AWS, dont EC2 et Lambda (chapitre 6). Le service est entièrement gratuit ; c’est la consommation de ressources qui est payante, à l’heure, en fonction du dimensionnement des ressources demandées.
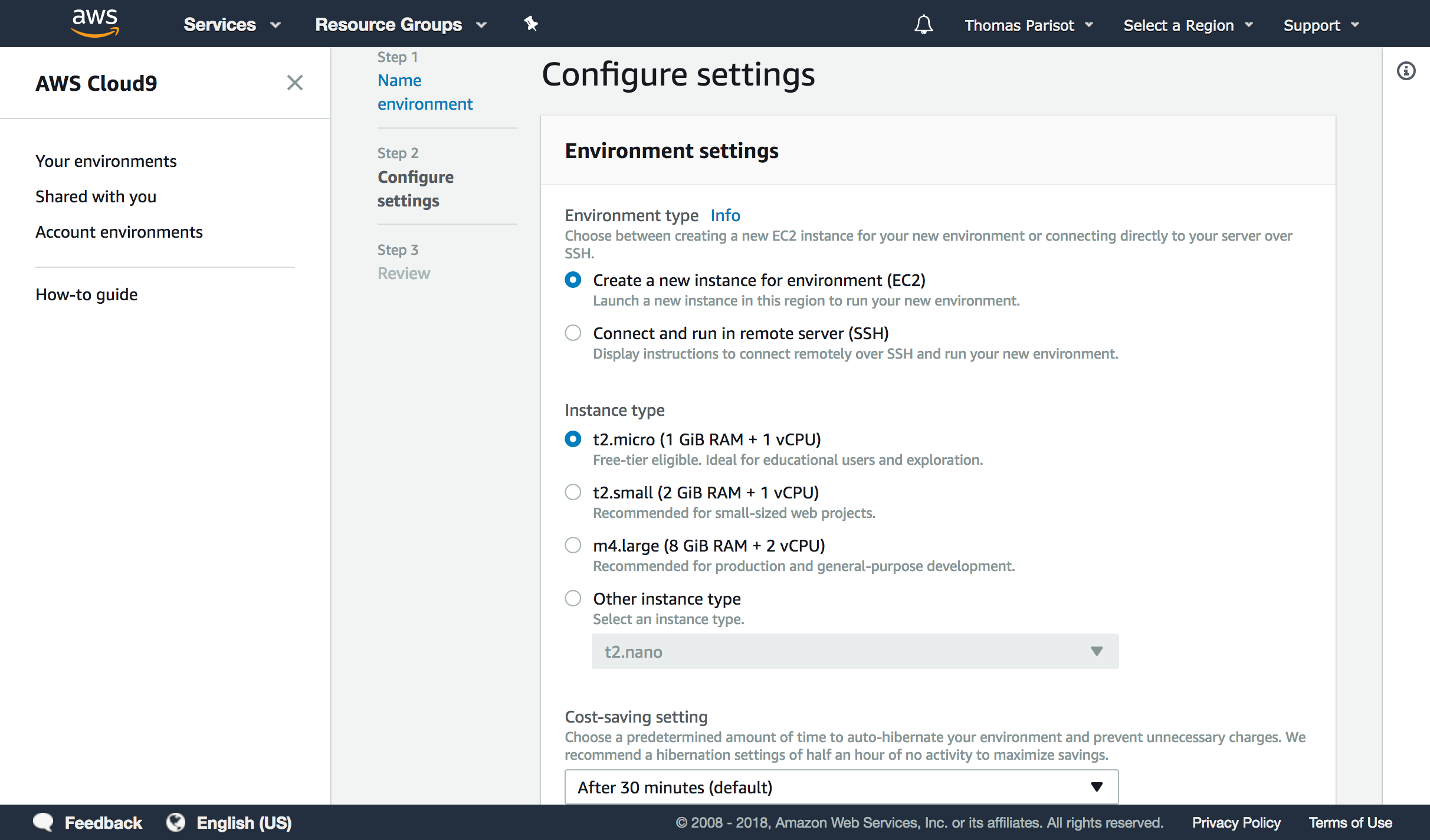
Cloud9 a peu d’opinions sur la manière dont votre environnement doit être configuré. Tout devra être configuré, des accès à votre compte GitHub à la version de Node à installer.
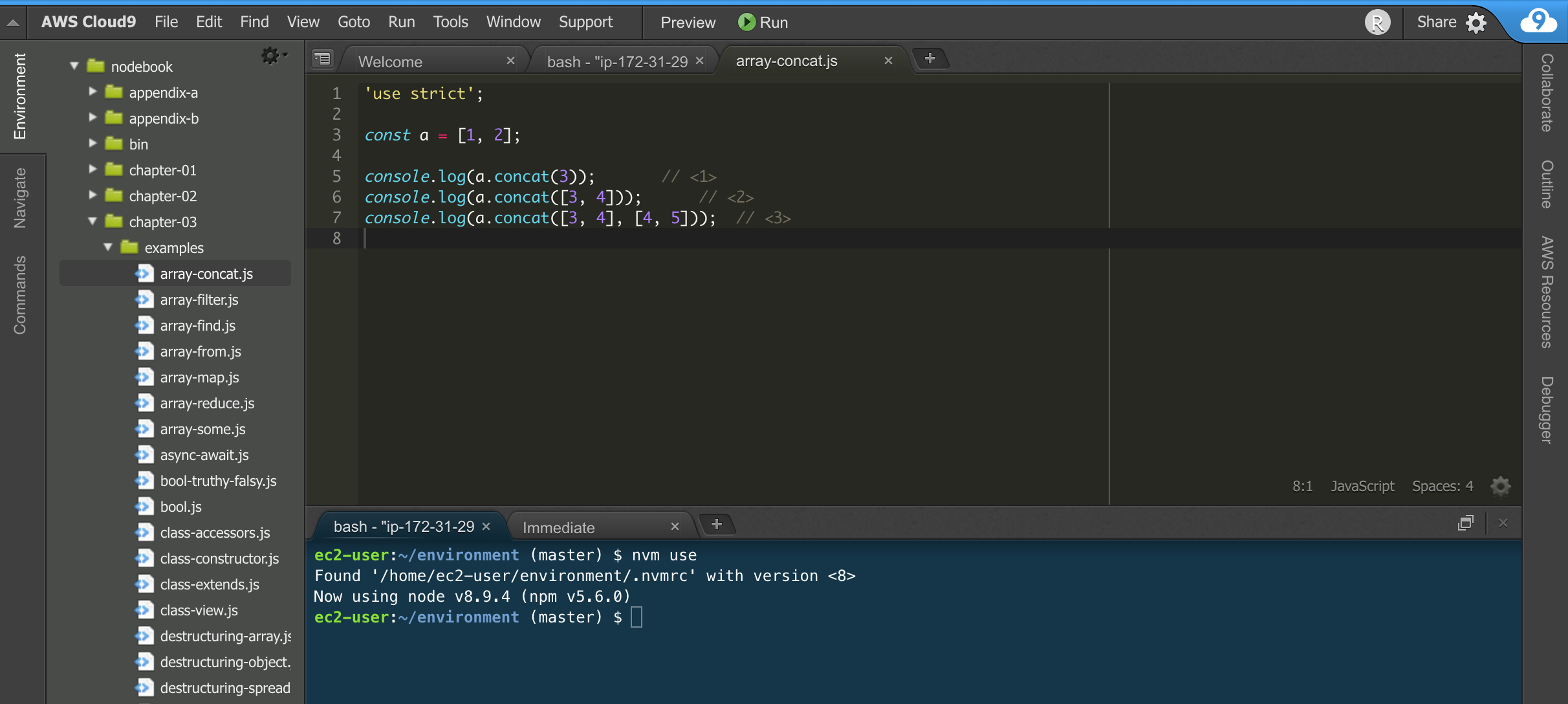
Cela tombe bien, nvm est préinstallé sur chaque espace de travail.
3.2. Plusieurs versions sur la même machine (nvm)
nvm est l’acronyme de Node Version Manager.
Ce logiciel permet d'installer plusieurs versions de Node sur un même ordinateur.
Si vous êtes sous Windows, nvm-windows offre exactement
les mêmes fonctionnalités (voir encadré).
Si vous venez d’un autre univers de programmation,
nvm est l’équivalent de rvm ou rbenv dans le monde Ruby, de phpenv dans
le monde PHP ou encore de virtualenv pour Python.
Le programme s’obtient à l’adresse suivante : github.com/creationix/nvm.
|
💡
|
Alternatives
nvm pour Windows
|
curl -L https://github.com/creationix/nvm/raw/v0.33.11/install.sh | bash
|
💡
|
Alternative nvm sous macOS
Rendez-vous dans la section « macOS » pour en savoir plus. |
Nous sommes libres d’installer toutes les versions de Node qui nous intéressent
en appelant la commande nvm install dans un terminal.
nvm install v10 nvm install v9
Dans cet exemple, nous installons deux versions de Node sur le même
ordinateur.
La version active est la dernière installée.
On retrouve à tout moment les versions installées avec la commande nvm ls.
nvm lsnvm ls
-> v10.9.0
v9.0.0
system
default -> v10 (-> v10.9.0) (default)
Cet exemple détaille la liste des versions de Node installées et celle des alias – associations entre un libellé et une version.
La commande nvm use nous fait naviguer entre des versions différentes de Node.
L’utilisation répétée de nvm use v10 et de
nvm use v9 nous fera aller et venir entre ces deux versions,
sans rien perdre de ce que nous étions en train de faire.
La commande nvm --help affiche de l’aide à propos des commandes disponibles.
J’utilise principalement les suivantes :
-
nvm install: installe ou met à jour une version de Node. -
nvm ls: liste les versions installées. -
nvm use: bascule vers une version donnée. -
nvm alias <nom> <version>: crée un alias nommé vers une version. -
nvm run <version> <script>: exécute un script Node dans une version donnée.
Quand nous avons fixé une version de Node à utiliser au quotidien,
l’alias spécial default en fait la version qui est systématiquement activée :
nvm alias default 10
La commande nvm use nous sert alors à activer une autre version pendant
la durée nécessaire à notre expérimentation.
3.3. Distributions Linux : Debian/Ubuntu et RedHat/CentOS
Ces distributions Linux listent Node dans leurs paquets officiels.
Un simple apt-get install nodejs et ça fonctionne !
Ou presque, car bien souvent on écopera d’une vieille version de Node.
Des paquets officiels pour Debian (≥ jessie), Ubuntu (≥ 12.04), Mint, RedHat Enterprise Linux (RHEL) et CentOS sont maintenus sur github.com/nodesource/distributions.
L’installation de Node 10.x sous Ubuntu et Mint se résume aux commandes suivantes :
sudo su curl -sL https://deb.nodesource.com/setup_10.x | bash - sudo apt-get install -y nodejs
Pour Debian, il faudra se mettre en root et ensuite saisir ces commandes :
curl -sL https://deb.nodesource.com/setup_10.x | bash - apt-get install -y nodejs
Pour RHEL et CentOS, il faudra se mettre en root et saisir la commande suivante :
curl -sL https://rpm.nodesource.com/setup_10.x | bash -
3.4. Distributions Linux : les autres
Des paquets officiels pour d’autres distributions que Debian, Ubuntu et Mint sont maintenus et accessibles par le biais des gestionnaires de paquets habituels :
-
Gentoo :
emerge nodejs -
Fedora (≥ 18) :
sudo yum install nodejs npm -
Arch Linux :
pacman -S nodejs -
FreeBSD, OpenBSD :
pkg install node
La liste à jour est maintenue sur le site officiel de Node : nodejs.org/fr/download/package-manager.
Notez que vous pouvez aussi utiliser nvm pour gérer vos versions de Node indépendamment du cycle de vie de votre système d’exploitation Linux.
3.5. macOS
Un installeur officiel pour macOS est fourni sur le site de Node, à l’adresse nodejs.org/fr/download/.
nvm est la voie alternative recommandée pour gérer plusieurs versions de Node en parallèle.
Il est toutefois possible d’installer Node et nvm via le gestionnaire de
paquets Homebrew (brew.sh).
Il aide à installer des logiciels qui ne sont pas distribués via le
Mac App Store.
-
Installer les Command Line Tools pour compiler des logiciels depuis leur code source.
-
Installation Homebrew.
xcode-select --install /usr/bin/ruby -e "$(curl -fsSL https://git.io/brew-install)"
Pour installer nvm, il suffit alors de lancer la commande suivante :
brew install nvm
Ou, pour installer une seule version de Node, la plus récente :
brew install node
Vous obtiendrez des options d’installation et de configuration en tapant
brew info nvm et/ou brew info node.
3.6. Windows
Un installeur officiel pour Windows est fourni sur le site de Node à l’adresse nodejs.org/fr/download/.
nvm-windows est la voie alternative recommandée pour gérer plusieurs
versions de Node en parallèle.
L’installeur officiel créera plusieurs raccourcis dans le dossier du menu :
Le menu créé par l’installeur contient deux icônes que nous utiliserons tout au long de la lecture de cet ouvrage :
-
: un terminal pour jouer avec JavaScript et voir les résultats que Node va interpréter ;
-
: un terminal pour exécuter nos programmes écrits en JavaScript.
Si vous utilisez déjà un gestionnaire de paquets comme Scoop (scoop.sh) ou Chocolatey (chocolatey.org), le chemin d’installation vers Node s’en trouvera réduit à une simple commande :
scoop install nodejs
choco install nodejs
|
🚨
|
Attention Versions de Windows
Node n’est pas compatible avec les versions antérieures à Vista. Cela inclut Windows XP. Mieux vaudra utiliser un service en ligne pour essayer Node sur votre ordinateur ou passer à Linux pour lui redonner une seconde vie en toute sécurité ! |
3.7. Raspberry Pi
Des binaires sont disponibles pour les microcontrôleurs fonctionnant avec des processeurs ARM v6/7/8, au cœur de ce que l’on appelle Internet des Objets (Internet of Things, IoT). Ces petits ordinateurs consomment peu d’énergie, disposent d’une connectique pour se relier à Internet et s’interfacent avec toutes sortes de capteurs.
Un paquet deb est également proposé pour les utilisateurs du
système d’exploitation Raspbian (www.raspbian.org).
Les instructions d’installation sont identiques à celles décrites
dans la section relative aux distributions Linux Debian.
curl -SLO https://nodejs.org/dist/v10.9.0/node-v10.9.0-linux-arm64.tar.xz tar -xJf "node-v10.9.0-linux-arm64.tar.xz" -C /usr/local --strip-components=1 ln -s /usr/local/bin/node /usr/local/bin/nodejs
Tous les binaires et les instructions d’installation sont disponibles sur nodejs.org/fr/download/.
3.8. Compiler depuis les sources
Certaines situations exigeront que vous compiliez Node. C’est le cas si vous cherchez à travailler au plus près du système sur lequel vous comptez déployer vos applications. Je pense par exemple à des architectures à processeur ARM, PowerPC, IBM System/390 ou bien à des systèmes Android, OpenBSD ou AIX.
La compilation manuelle est également intéressante pour régler plus finement
certains aspects de Node : rendre le binaire indépendant des
bibliothèques système (statique), le module http/2,
langues et fuseaux horaires fonctionnels avec l’API ECMA 402 Intl,
options de sécurité liées à OpenSSL, mais aussi l’intégration avec des
profileurs et débogueurs externes (type XCode, GNU Debugger, Intel VTune).
curl -sS https://nodejs.org/dist/v10.9.0/node-v10.9.0.tar.gz \ | tar -zxf - cd node-v10.9.0 ./configure && make && make install
La compilation manuelle requiert la présence de GCC (≥ 4.9), de Python (≥ 2.6) et de GNU Make (≥ 3.81).
Les instructions de compilation varient d’un système d’exploitation à l’autre. Consultez les dépendances et instructions complètes à l’adresse suivante : github.com/nodejs/node/blob/master/BUILDING.md.
3.9. Images Docker
Docker (docker.com) est un outil open source dit d'applications en conteneur. Une de ses qualités principales est d'isoler l’exécution d’applications de leur environnement. Une image Docker décrit la recette d’installation d’une application. L’environnement d’exécution Docker fait office de "passe-plat" avec le système d’exploitation. Une image Docker fonctionne ainsi de la même manière, qu’elle soit exécutée sous Linux, macOS ou encore Windows.
Les installeurs et instructions d’installation de Docker se trouvent à l’adresse docker.com/community-edition.
Une fois Docker installé, on peut exécuter une image officielle pour Node v10.
docker run -ti --rm node:10 node --version v10.9.0
Ici, Docker télécharge l’image node:10 et exécute la commande
node --version dans un contexte isolé du système d’exploitation.
Pour lancer un terminal Node dans Docker, il faudrait saisir la commande suivante :
docker run -ti --rm node:10 node 2+2 4
Plusieurs variantes d’images Node se trouvent à notre disposition :
- standard (
node:10) -
Base Linux Debian pour tout type d’applications Node.
- Debian (
node:10-wheezy) -
Comme standard mais sur des bases Debian différentes, comme Wheezy, Stretch, etc..
- Alpine (
node:10-alpine) -
Distribution spécialement créée pour Docker (alpinelinux.org), qui pèse à peine quelques Mo.
- Allégée (
node:10-slim) -
Base Linux Debian sans outillage parfois nécessaire à des modules Node – utile si vous souhaitez économiser de l’espace disque.
L’intégralité des versions et architectures prises en charge est disponible sur le catalogue Docker Hub : hub.docker.com/_/node/.
Nous reviendrons sur ce sujet dans la section “Déploiement d’une image Docker” du chapitre 6.
4. Vérifier l’installation de Node depuis un terminal (shell)
Nous avons installé un environnement d’exécution Node dans la section précédente. Pour vérifier que tout s’est bien déroulé, ouvrez un terminal et saisissez la commande suivante :
node --version v10.9.0
Le numéro de version du Node fraichement installé devrait apparaître. Si le mot terminal ne vous parle pas, la suite de cette section va vous éclairer – vous pourrez ensuite revenir essayer cette commande.
4.1. Qu’est-ce qu’un terminal ?
Le terminal est notre compagnon pour dialoguer avec le système d’exploitation. L'invite de commandes est son nom véritable. Ce nom nous donne un indice sur la fonction de ce type de logiciel : inviter l’utilisateur à saisir des commandes pour obtenir des résultats calculés par un ordinateur.
|
💬
|
Histoire Terminal physique
L’histoire des invites de commande remonte au temps où les ordinateurs étaient plus volumineux que nos logements. Une époque lointaine où les ordinateurs étaient véritablement et physiquement distants des claviers qui les interrogeaient. Pour en savoir plus : fr.wikipedia.org/wiki/Terminal_informatique. |
Un terminal est notre moyen privilégié pour interagir avec Node lorsqu’il est installé sur un ordinateur. Les systèmes d’exploitation en ont pour la plupart un installé par défaut. Cela vaut également pour la majorité des services en ligne.
4.2. Choisir un terminal
Voici une liste non exhaustive d’applications de type terminal :
- macOS
-
-
Terminal.app : fourni par défaut (dans ) ;
-
iTerm2 : une version améliorée disponible sur iterm2.com (ou
brew cask install iterm2) ;
-
- Linux
-
-
GNOME Terminal : fourni par défaut sous Debian, Ubuntu et les distributions utilisant le bureau GNOME (wiki.gnome.org/Apps/Terminal) ;
-
Terminator : un autre terminal populaire (gnometerminator.blogspot.com) ;
-
- Windows
-
-
Node.js Command Prompt : fourni avec l'installeur Windows ;
-
PowerShell : fourni par défaut depuis Windows 7, sinon disponible sur github.com/PowerShell/PowerShell – également disponible pour macOS et Linux.
-
Maintenant que nous avons installé Node et compris comment y accéder depuis notre système d’exploitation ou navigateur web, attaquons-nous au dernier morceau du puzzle : avec quel logiciel écrire du code JavaScript pour nos applications Node ?
5. Choisir un éditeur de texte
Programmer pour Node revient dans la majorité des cas à écrire du JavaScript. À cela s’ajoutent le HTML et le CSS dans le cas d’applications ou de sites web.
À la base, si un éditeur de texte suffit pour écrire du code, prenons le temps de regarder ce qui pourrait nous apporter un peu de confort dans le processus d’écriture.
Les logiciels présentés ci-après couvrent bon nombre de fonctionnalités qui améliorent de près ou de loin notre capacité à écrire du code de qualité. Parmi elles, on retrouve la coloration syntaxique, l’inspection dynamique, le débogage, des astuces de productivité et d’intégration à l’écosystème Node.
Cette sélection a pour but de vous aider à piocher au plus près de vos goûts. Le meilleur logiciel sera celui qui vous plaira. Rien n’empêche d’en changer par la suite.
5.1. Atom
Atom (atom.io) est un éditeur de code open-source, multilingue et multi plate-forme, dont le développement a été lancé par la société commerciale GitHub (github.com). Le logiciel est basé sur Electron, un environnement d’exécution d’applications de bureau reposant sur les technologies web et sur Node !
Atom offre un écosystème d’extensions pour étendre les fonctionnalités de l’éditeur. On retrouvera des extensions dédiées à l’auto-complétion, un débogueur Node intégré (pour exécuter nos programmes sans changer de fenêtre), mais aussi une vérification syntaxique sur mesure.
Toutes les extensions d’Atom sont disponibles sur atom.io/packages ; voici une liste de celles que j’utilise au quotidien :
- minimap (atom.io/packages/minimap)
-
Une prévisualisation de l’intégralité du code source d’un fichier.
- file-icons (atom.io/packages/file-icons)
-
Une manière plus agréable de visualiser les différents types de fichiers en fonction de leur icône.
- pigments (atom.io/packages/pigments)
-
Affiche les couleurs en marge et dans le code source.
- language-babel (atom.io/packages/language-babel)
-
Coloration syntaxique de tous les langages compris par l’outil Babel (babeljs.io), dont les versions modernes de JavaScript, JSX, GraphQL, etc.
- emmet (atom.io/packages/emmet)
-
Génère du HTML à partir d’une écriture sous forme de sélecteur CSS.
- linter-eslint (atom.io/packages/linter-eslint)
-
Vérification syntaxique basée sur les règles projet du module ESLint (eslint.org, voir l'annexe).
- atom-ternjs (atom.io/packages/atom-ternjs)
-
Autocomplétion pour JavaScript, Node et d’autres bibliothèques populaires comme jQuery, chai et underscore.
- editorconfig (atom.io/packages/editorconfig)
-
Adapte les réglages d’indentation et autres styles d’écriture de code documentés dans chaque projet.
- language-sass (atom.io/packages/language-sass)
-
Prise en charge du langage Sass.
- markdown-writer (atom.io/packages/markdown-writer)
-
Raccourcis et aides pour formater du texte au format Markdown.
- autocomplete-modules (atom.io/packages/autocomplete-modules)
-
Étend l’autocomplétion lors des appels aux modules
npm(chapitre 5). - linter-sass-lint (atom.io/packages/linter-sass-lint)
-
Vérification syntaxique des fichiers Sass.
- node-debugger (atom.io/packages/node-debugger)
-
Intégration du débogueur Node.
- tablr (atom.io/packages/tablr)
-
Éditeur de fichiers CSV.
- linter-markdown (atom.io/packages/linter-markdown)
-
Vérification syntaxique des fichiers Markdown.
- node-resolver (atom.io/packages/node-resolver)
-
Navigation au sein des modules
npmen cliquant sur leurs méthodes ou propriétés.
|
💡
|
Productivité Installer vos extensions favorites
Chaque extension peut être ajoutée à nos favoris sur le site atom.io, aussi bien pour signaler que nous l’apprécions que pour la retrouver plus tard. 
Figure 12. Une extension Atom ajoutée aux favoris
Le logiciel nous offre une commande à saisir dans un terminal pour installer toutes les extensions de nos favoris : apm stars --install |
5.2. Visual Studio Code
Visual Studio Code (code.visualstudio.com) est un éditeur de code open source, multilingue et multi plate-forme dont le développement a été lancé par la société Microsoft. Le logiciel est basé sur Electron, un environnement d’exécution d’applications de bureau reposant sur les technologies web et sur Node.
Le système IntelliSense est un de ses atouts principaux.
Il se sert du contexte disponible pour offrir une auto-complétion
et des bulles d’aide pertinentes.
C’est un éditeur parfaitement adapté au développement d’applications Node
grâce à des fonctionnalités natives comme l’exécution, le débogage,
la gestion de tâches et le versionnement – du code et des modules npm.
Visual Studio Code se complète d’un mode Node (code.visualstudio.com/Docs/runtimes/nodejs) et d’une place de marché (marketplace.visualstudio.com/VSCode) pour étendre ses fonctionnalités.
5.3. WebStorm
WebStorm (www.jetbrains.com/webstorm/) est un environnement de développement (IDE) payant dédié au développement web HTML5, JavaScript et Node.
Le logiciel est commercialisé par la société JetBrains, renommée pour ses IDE Pycharm (pour Python), PhpStorm (pour PHP) et IntelliJ IDEA (pour Java).
WebStorm est compatible Windows, Linux et macOS.
Ses forces résident dans sa relative légèreté,
une auto-complétion intelligente prenant en compte la résolution
des modules CommonJS et AMD, une intégration des outils populaires
dans l’écosystème Node (npm, ESLint, Mocha, Karma, Bower, etc.)
ainsi qu’un débogage avancé.
Le téléchargement de WebStorm inclut une période d’essai de 30 jours. La tarification du produit varie selon que vous soyez un individu ou une entreprise et que le paiement soit mensuel ou annuel.
|
💡
|
Astuce Licence open source
Vous pouvez demander à bénéficier d’une licence gratuite sous réserve d’une preuve de contribution à un ou plusieurs projet(s) open source. Rendez-vous sur www.jetbrains.com/buy/opensource/. |
5.4. Visual Studio IDE
Visual Studio (www.visualstudio.com/vs/) est un environnement de développement édité par Microsoft. Historiquement dédié au développement applicatif Windows (Visual Basic, Visual C++), ce logiciel gère aujourd’hui bien plus de langages, dont C#, HTML, CSS, JavaScript, ASP.Net. Il est surtout extensible, ce qui permet de lui ajouter Python ou encore Node, entre autres.
Visual Studio est compatible Windows uniquement. Il existe en plusieurs versions, parmi lesquelles la Community qui est gratuite.
Afin de bénéficier de l’intégration complète de l’écosystème Node, il est nécessaire d’installer l’extension Node.js Tools for Visual Studio (aussi nommée NTVS). Elle est gratuite, open source et disponible à l’adresse suivante : www.visualstudio.com/vs/node-js/.
6. Quand mettre à jour Node.js ?
Le développement de Node continue pendant que vous lisez ces lignes. Les sections suivantes présentent les différentes raisons pour lesquelles de nouvelles versions de Node sont distribuées.
Quelle que soit la raison, la mise à jour est identique à l'installation initiale de Node :
-
Si vous aviez utilisé un installeur : téléchargez et installez la nouvelle version.
-
Si vous aviez utilisé un gestionnaire de versions : téléchargez la nouvelle version et indiquez qu’elle devient celle par défaut.
-
Si vous aviez compilé depuis les sources : téléchargez les sources de la nouvelle version et compilez à nouveau.
-
Si vous aviez utilisé une image Docker : téléchargez la nouvelle version en ayant recours à la commande
docker pull node:<version>.
6.1. Mises à jour de sécurité
Node n’est pas exempt de bogues. Une catégorie en particulier nécessite d’être réactif : les failles de sécurité. Ces failles offrent une surface d’attaque à des personnes mal intentionnées, qui seraient tentées d’accéder sans permission à des serveurs, et donc aux données qu’ils contiennent.
L’impact peut être faible pour un site personnel, à condition de ne pas laisser traîner de mots de passe ici et là. Cela risque de se révéler beaucoup plus fâcheux pour un site e-commerce ou une entreprise dont la santé serait mise en jeu.
L’équipe de Node livre des versions corrigeant les failles de sécurité aussitôt qu’elle le peut. Une faille n’est d’ailleurs pas révélée avant que le correctif soit disponible, par mesure de précaution.
Que faire si la faille de sécurité affecte la version de Node installée sur :
-
notre ordinateur de développement : c’est peu risqué, sauf si un module tiers l’exploite ;
-
notre site web : redéployez aussitôt le site en question avec une version corrigeant la faille.
Les versions de Node qui corrigent des failles de sécurité ou des bogues connus
n’ont quasiment aucun risque de casser une application existante.
On les appelle les versions patch.
Elles sont indiquées par le troisième numéro de version : v10.0.0, v10.0.1, …
Plusieurs ressources sont à notre disposition pour se tenir informé·e :
- Liste de diffusion (groups.google.com/group/nodejs-sec)
-
Pour recevoir l’alerte par courriel (moins d’une par mois).
- Blog Node.js (nodejs.org/en/blog/vulnerability/)
-
Une page web à consulter avec un navigateur. Les mêmes messages sont relayés sur la liste de diffusion.
- Fil RSS du blog Node.js (nodejs.org/en/feed/vulnerability.xml)
-
Comme le point précédent mais auquel on peut souscrire avec un lecteur RSS comme Feedly ou Mozilla Thunderbird.
- Compte Twitter @nodesecurity (twitter.com/nodesecurity)
-
Annonce des informations liées à la sécurité générale de Node et de son écosystème.
|
💬
|
Lien Groupe de travail Node.js Security
Un groupe de travail (github.com/nodejs/security-wg) veille à
maintenir et améliorer la sécurité de Node.
Ces personnes se chargent d’être proactives dans la détection
de failles dans l’architecture de Node, mais aussi dans
l’intégration de code tiers, comme la brique OpenSSL
ou le module |
Le chapitre 6 décrit
comment se maintenir à jour sur les
alertes de sécurité de nos
applications Node.
Celles-ci risquent notamment d’être vulnérables à cause des modules npm
dont elles dépendent – en plus des vulnérabilités de Node.
6.2. Versions mineures
Les versions mineures de Node sont celles qui lui ajoutent de
nouvelles fonctionnalités quasiment sans risque de casser une application existante.
Elles sont indiquées par le deuxième chiffre du numéro de version :
v10.0.3, v10.1.0, …
Les versions mineures sortent une petite dizaine de fois par an. Une migration ne demande pas nécessairement d’investir beaucoup de temps pour adapter et tester nos applications Node.
En cas de sortie d’une version mineure :
-
Sur notre ordinateur de développement : on peut migrer si l’on veut tester ou bénéficier des nouvelles fonctionnalités de cette version.
-
Sur notre site web : pas d’action immédiate requise. On peut migrer si l’on veut bénéficier des nouvelles fonctionnalités de cette version.
6.3. Versions majeures
Les versions majeures ajoutent également de nouvelles fonctionnalités à Node, mais elles peuvent être amenées à changer des comportements qui casseraient une application existante.
Elles sont indiquées par le premier chiffre du numéro de version :
v10.0.0, v11.0.0, …
Les versions majeures sortent deux fois par an. Une migration peut demander de consacrer un certain temps à adapter et à tester nos applications Node.
En cas de sortie d’une version majeure :
-
Sur notre ordinateur de développement : nous prenons du temps pour tester nos applications et nous assurer de leur bon fonctionnement.
-
Sur la machine de production : il n’y a pas d’action immédiate requise.
6.4. Comprendre le cycle de vie produit
Le développement de la plate-forme Node prend soin de ne pas aller trop vite ni d’altérer la stabilité des applications et des outils en fonctionnement. Il sort au maximum deux versions majeures par an, dont une est maintenue à long terme (Long Term Support, LTS).
La notion de version LTS a été introduite pour donner un repère de stabilité. On sait qu’on peut compter dessus sans se poser de question. Les autres versions sont à voir comme des coups d’essai, dans l’anticipation d’une migration vers une version suivante, maintenue à long terme.

|
💬
|
Lien Calendrier de sorties
Le calendrier des sorties de Node est tenu à jour sur github.com/nodejs/Release. Référez-vous à ce calendrier pour des informations à jour sur les prochaines versions et l’arrêt de maintenance des plus anciennes. |
Si on récapitule : - Les versions impaires (v5, v7, etc.) - sont développées pendant neuf mois ; - ne sont pas maintenues au-delà. - Les versions paires (LTS, v10, etc.) - sont basées sur la version impaire précédente ; - sont développées pendant six mois ; - sont maintenues LTS pendant dix-huit mois ; - basculent en maintenance pendant douze mois supplémentaires ; - ne sont pas maintenues au-delà.
Les patchs de sécurité ne concernent que les versions en développement, LTS ou en maintenance.
Cette planification garantit une plate-forme et un ensemble de
fonctionnalités stables de manière prédictible,
à la fois pour les projets reposant sur Node, mais aussi
pour l’écosystème de contributeurs de modules npm.
7. Conclusion
Nous sommes désormais en mesure d’installer et mettre à jour Node sur notre ordinateur. Nous savons aussi avec quel(s) logiciel(s) développer nos applications et où nous informer pour savoir quand faire nos mises à jour, pour corriger des problèmes de sécurité et bénéficier des nouvelles fonctionnalités du langage.
Le prochain chapitre nous amènera à reprendre les bases du langage JavaScript en jouant avec le terminal Node. On découvrira également les différences entre JavaScript, ECMAScript et Node.