|
💡
|
Vous êtes en train de lire le Chapitre 4 du livre “Node.js”, écrit par Thomas Parisot et publié aux Éditions Eyrolles. L’ouvrage vous plaît ? Achetez-le sur Amazon.fr ou en librairie. Donnez quelques euros pour contribuer à sa gratuité en ligne. |
Nous allons faire un tour d’horizon des capacités de Node et de son système de modules pour nous interfacer avec les systèmes d’exploitation Linux, macOS et Windows.
-
Interagir avec l’interpréteur Node
-
Les modules de base
-
Créer ses propres modules
-
S’en sortir quand ça ne se passe pas comme prévu
-
Les différences de JavaScript entre Node et les navigateurs web
-
Options utiles pour démarrer Node
Après avoir exécuté notre premier script Node, nous allons découvrir l’étendue des modules Node et ce qu’ils nous offrent en termes de capacité d’interaction avec le système d’exploitation – disque, réseau, calculs, etc.
Nous apprendrons ensuite à créer et organiser nos propres modules – nous découvrirons comment les partager et les distribuer dans le chapitre 5.
Enfin, nous passerons en revue des erreurs typiques pour apprendre à les lire et à mieux réagir avant de terminer sur des manières alternatives d’exécuter des scripts Node, par exemple pour débogueur ou charger d’autres modules.
|
💬
|
Remarque Versions de Node et npm
Le contenu de ce chapitre utilise les versions Node v10 et npm v6. Ce sont les versions stables recommandées en 2022. |
5. Interagir avec l’interpréteur Node
L’interpréteur Node est le programme qui nous fournit des résultats en échange d’instructions ECMAScript. Le terminal est un autre programme permettant de faire dialoguer un ordinateur avec les programmes installés.
|
💬
|
Le chapitre 2 détaille comment installer Node et un terminal. Il contient également des conseils pour utiliser Node depuis un navigateur web. Cela peut rendre l’accès au terminal plus facile. |
Ce chapitre se base sur le principe que vous avez un terminal installé, sur lequel vous allez saisir des instructions ECMAScript.
|
💡
|
Pratique Jouer avec les exemples dans un terminal
Les exemples titrés d’un nom de fichier peuvent être installés sur votre ordinateur. Exécutez-les dans un terminal et amusez-vous à les modifier en parallèle de votre lecture pour voir ce qui change. Installation des exemples via le module npm
nodebooknpm install --global nodebook nodebook install chapter-04 cd $(nodebook dir chapter-04) La commande suivante devrait afficher un résultat qui confirme que vous êtes au bon endroit : node hello.js Suivez à nouveau les instructions d’installation pour rétablir les exemples dans leur état initial. |
5.1. Afficher la version
Commençons par afficher la version de l’interpréteur Node. Nous nous assurons ainsi que nous pouvons interagir avec lui avec succès et qu’il est celui que nous attendons, dans la bonne version. La version de Node conditionne la liste des fonctionnalités du langage ECMAScript à disposition.
|
💡
|
Compatibilité Syntaxe ECMAScript
Le site web node.green liste le niveau de compatibilité des fonctionnalités ECMAScript. Cette page vous aidera à comprendre quelles fonctionnalités utiliser en toute sécurité, version par version de Node. |
Une fois votre terminal ouvert, saisissez la commande suivante :
node --version
Le numéro de version de l’interpréteur Node s’affiche alors,
par exemple v10.9.0.
Si c’est ce à quoi vous vous attendiez, passez à la suite. À l’inverse, si une erreur se produit ou si la version n’est pas la bonne, retournez à la section “Installer Node.js” du chapitre 2.
5.2. Avec un script
L’exécution d’un script Node est très certainement la pratique la plus courante.
L’interpréteur Node lit le contenu d’un fichier et exécute les instructions. L’interpréteur reste actif jusqu’à ce que toutes les instructions soient traitées.
console.log(2 + 2);
console.log('abc'.toLocaleUpperCase());Le fichier exemple script.js contient deux instructions.
Node les interprète lorsqu’on lui passe le chemin du fichier en paramètre
dans une invite de commandes :
node script.js 4 ABC
Node nous rend ensuite la main pour exécuter d’autres commandes.
On apprendra à passer des arguments d’exécution
dans la section sur le module process.
|
💡
|
Performances Ressources machine
Démarrer un processus Node a un coût incompressible en ressources machine : environ 30 Mo de RAM et 40 ms de CPU avant d’exécuter nos instructions. |
5.3. Avec l’invite de commandes interactive (REPL)
L’invite de commandes interactive est un moyen de parler à l’interpréteur Node sans écrire de fichier. Je l’utilise pour tester des idées et des éléments de syntaxe quand je ne m’en rappelle plus.
Le mode interactif s’active en exécutant Node sans aucun argument :
node
On notera au passage que l’invite est préfixée par le caractère `>`
afin de marquer notre présence dans un environnement différent.
On retrouve un comportement similaire dans les invites de commande
des langages Ruby (irb), Python (python) et PHP (php -a)
Lorsque nous sommes dans l’interpréteur interactif, toutes les expressions sont interprétées par Node :
node 2 + 2 4 "abc".toLocaleUpperCase() 'ABC'
Des expressions sont réservées pour obtenir de l’aide, sortir de l’interpréteur
ou simplement nettoyer ce que l’on voit à l’écran.
Pour cela on fait appel à l’instruction .help :
node .help .break Sometimes you get stuck, this gets you out .clear Alias for .break .editor Enter editor mode .exit Exit the repl .help Print this help message .load Load JS from a file into the REPL session .save Save all evaluated commands in this REPL session to a file
Les touches ou combinaisons de touches suivantes sont utiles pour naviguer dans l’invite de commandes :
-
Ctrl+C annule la saisie de la ligne en cours – c’est ⌃+C sous macOS.
-
⬆ et ⬇ aident à naviguer dans l’historique des commandes.
-
TAB tente de compléter la saisie avec une expression ou variable connue.
node consoTAB console console.TAB ... console.assert console.clear console.count ...
On notera que l’utilisation de TAB après un caractère point (.)
liste l’intégralité des propriétés de cet objet.
|
💡
|
Raccourci Afficher toutes les variables connues
La touche TAB affiche toutes les variables connues de la session interactive en cours. Il suffit d’appuyer une ou deux fois dessus dans une invite vide : node TABTAB Array Boolean Date Error EvalError Function Infinity JSON Math NaN Number Object ... C’est un excellent moyen de découvrir des éléments du langage qui nous étaient inconnus jusque-là. |
La sortie de l’invite de commandes se fait à l’aide de l’utilisation répétée de la combinaison de touches Ctrl+C (ou ⌃+C sous macOS). On revient ainsi à l’état initial où l’on était avant de saisir la commande `node` :
node (To exit, press ^C again or type .exit)
Ce même résultat s’obtient en saisissant .exit
ou en utilisant la combinaison de touches Ctrl+D (ou ⌃+D sous macOS).
|
💡
|
Raccourci Variable magique
_La variable node 2 + 2 4 _ + 2 6 Elle est équivalente à la variable |
6. Les modules de base
Les modules de base étendent le champ d’action de Node. Ils servent d’interfaces pour communiquer avec le système d’exploitation, le système de fichiers, des ressources HTTP et des connexions réseau, entre autres. Ils sont inclus avec chaque installation de Node. On peut donc en bénéficier sans effort supplémentaire.
Un module de base se charge en passant son identifiant
à la fonction require(), qui retourne alors un objet avec un certain nombre
de propriétés et de fonctions.
Ainsi, on charge le module fs (pour file system – système de fichiers)
afin d’interagir avec les fichiers et les répertoires présents sur l’ordinateur :
const fs = require('fs'); // (1)
fs.readdir('.', (error, files) => { // (2)
console.log(files); // (3)
});-
On charge les fonctions et attributs du module
fsdans la variable du même nom (on pourrait l’appeler autrement). -
L’appel à la fonction
fs.readdir()passe un objet d’erreur ainsi que la liste des fichiers et répertoires contenus dans le chemin indiqué. -
Affiche un tableau contenant les noms de fichiers et de répertoires présents dans le dossier courant.
Ces modules de base représentent la pierre angulaire de nos applications Node.
Ils fournissent le nécessaire pour tout faire !
On apprendra à étendre encore plus le champ des possibles dans
le chapitre 5,
grâce aux modules npm.
Les modules de base changent au fil du temps : les nouvelles versions de Node ajoutent, corrigent et complètent les modules et fonctions existants. La documentation officielle de Node reflète ces changements et affiche un indice de stabilité pour savoir à quoi s’en tenir.

fs et son indice de stabilitéExceptionnellement, un module de base (ou une de ses fonctions) peut être supprimé. L’équipe de Node annonce ces changements en dépréciant le module en question : le code reste en place et sera supprimé dans une version ultérieure. En général, c’est une question de mois voire d’années. On verra plus loin comment afficher les alertes de dépréciation.
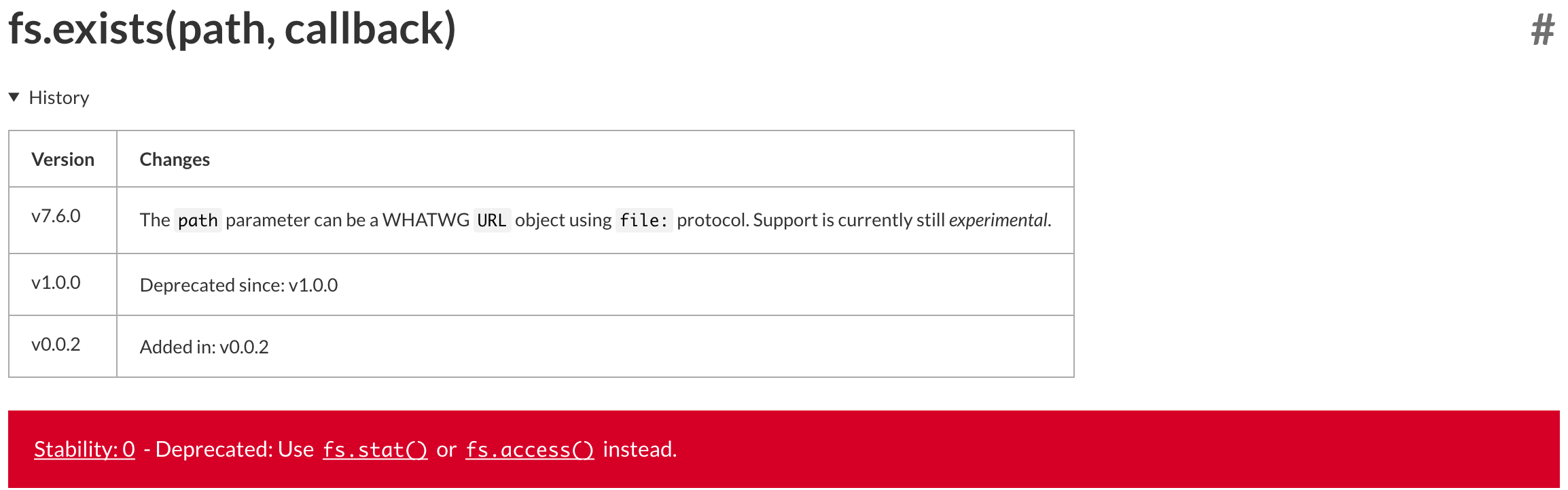
fs.exists(), affichée comme dépréciée depuis Node v1|
💬
|
Documentation Lecture des indices de stabilité
Node communique un indice de stabilité pour les modules de base. Cette échelle se décompose en trois niveaux :
L’indice est parfois appliqué à des fonctions dont les attentes changeraient d’une version à l’autre de Node. |
Les sections suivantes illustrent des usages courants des modules de base pour mieux comprendre ce qu’on peut en attendre et comment les utiliser.
6.1. console : déboguer rapidement des variables
L’objet console est une boîte à outils pour afficher
ce qui se passe à un moment donné dans un de nos scripts.
let count = 0;
count++; count++; count++;
console.log('Valeur de count :', count);La fonction écrit les messages et la valeur des variables dans la sortie standard du terminal :
node console/log.js Valeur de count : 3
|
💡
|
Raccourci Variable globale console
Node charge automatiquement le module pour nous et
le rend utilisable à tout moment à travers la variable globale Il est donc inutile de charger le module manuellement avec |
console.log() sait interpoler les valeurs passées en argument avec le marqueur %s.
C’est utile pour structurer un message complexe en gardant les variables à part :
console.log('Soupe %s et carottes', 'lentilles'); // (1)-
Affiche
Soupe lentilles et carottes.
%s ne sait afficher que des chaînes de caractères.
D’autres marqueurs savent afficher d’autres types de données :
%d
|
Affiche la valeur en tant que nombre. |
%j
|
Affiche la valeur en tant que structure JSON. |
%O
|
Affiche l’objet avec une profondeur maximum de 4 éléments. |
%o
|
Idem que |
console.log()
|
Affichage de messages et de variables dans le terminal. |
console.error()
|
Comportement identique à |
console.dir()
|
Affichage dédié aux objets et tableaux. On peut paramétrer la profondeur d’affichage (par défaut, jusqu’à deux niveaux). |
console.group()
|
Regroupe visuellement les appels à |
console.time()
|
Démarre un chronomètre en lui attribuant un nom.
Le chronomètre s’arrête et sa durée s’affiche avec |
classe Console
|
Crée un objet similaire à |
|
💡
|
Web Console et navigateurs web
L’objet 
Figure 4. Console web dans le navigateur web Firefox
|
|
💬
|
Documentation Module console
La documentation du module |
6.2. path : manipuler des chemins de fichiers
Le module path offre un ensemble de fonctions et de propriétés pour
manipuler et construire des chemins vers des fichiers et répertoires.
Ces opérations permettent à notre code de fonctionner de manière identique sur des systèmes d’exploitation qui expriment différemment les chemins – Linux et Windows par exemple.
const path = require('path');
console.log(path.dirname('/tmp/package.json')); // (1)
console.log(path.basename('/tmp/package.json')); // (2)
console.log(path.extname('/tmp/package.json')); // (3)-
Affiche
/tmp. -
Affiche
package.json. -
Affiche
.json.
Certaines fonctions comme path.join() tiennent compte de la nature du système
d’exploitation.
Le résultat d’un même appel de fonction sera différent, mais correspondra
à la même intention :
const path = require('path');
console.log(path.sep); // (1)
console.log(path.join('tmp', 'package.json')); // (2)-
Affiche
/(\sous Windows). -
Affiche
tmp/package.json–tmp\package.jsonsous Windows.
On constate que path.join() assemble les chemins en utilisant la valeur de
path.sep.
Ce qui est bien pour nous, c’est qu’on n’a pas besoin d’y penser :
Node se charge de la compatibilité avec le système d’exploitation.
La différence de résultats se précise un peu plus lorsque l’on tente de calculer des chemins complets, relatifs à notre emplacement actuel :
const path = require('path');
const relative_diff = path.relative(
'/tmp/package.json', '/tmp/source'
);
const resolve_diff = path.resolve(
'/tmp/package.json', '..', './source'
);
console.log(relative_diff); // (1)
console.log(resolve_diff); // (2)-
Affiche
../source(..\sourcesous Windows) – c’est ce qu’il faut parcourir pour aller du premier chemin au second. -
Affiche
/tmp/source(C:\tmp\sourcesous Windows) – on constate que le chemin résolu est absolu, et intègre la lettre du lecteur sous Windows.
Les résultats produits par les fonctions du module path
se combinent particulièrement bien avec celles du module fs, pour
accéder aux fichiers.
path.basename()
|
Retourne le nom de fichier. |
path.dirname()
|
Retourne le nom de répertoire. |
path.extname()
|
Retourne l’extension d’un fichier. |
path.isAbsolute()
|
Indique si le chemin est absolu ou non. |
path.join()
|
Assemble des bouts de chemin. |
path.parse()
|
Retourne des informations liées à la compréhension d’un chemin (extension, nom de fichier, nom de répertoire). |
path.relative()
|
Calcule le chemin relatif entre un chemin source et un de destination. |
path.resolve()
|
Calcule un chemin absolu à partir de plusieurs bouts de chemin. |
Attribut path.sep
|
Retourne le caractère servant de séparateur de répertoires
pour le système d’exploitation sur lequel est exécuté le script :
|
|
💡
|
Compatibilité Manipuler des chemins Windows sous Linux et vice-versa
On peut avoir besoin de manipuler des chemins Windows avec du code
exécuté sur un autre système d’exploitation comme Linux ou macOS.
C’est exactement ce que proposent les fonctions de path/win32.js
L’objet |
|
💬
|
Documentation Module path
La documentation du module |
6.3. url : manipuler des URL
Le module url offre des outils pour interpréter des URL, les transformer
et les assembler à nouveau sous forme de chaîne de caractères.
La variable URL (en majuscules) est disponible de manière globale.
const example = new URL('https://apprendre-nodejs.fr/v1/');
console.log(example.hostname); // (1)
console.log(example.pathname); // (2)-
Affiche
thom4.net. -
Affiche
/node.js/.
|
💡
|
Web Compatibilité avec les navigateurs
La classe |
L’objet retourné par le constructeur de URL est modifiable.
Il est ainsi possible de changer les parties de l’URL qui nous intéressent
et de récupérer une URL sous forme d’une chaîne de caractères :
const example = new URL('https://thom4.net');
example.pathname = '/';
example.hash = '#top';
console.log(example.toString()); // (1)-
Affiche
thom4.net/#top– le chemin et le fragment ont été modifiés.
La fonction format() va plus loin que url.toString().
Ses options contrôlent plus finement ce qui sera conservé ou retiré lors
de la conversion en chaîne de caractères.
const {format} = require('url');
const url = 'https://user:password@thom4.net/#top?test=1';
const example = new URL(url);
const options = {
auth: false,
search: false,
fragment: false,
};
console.log(format(example, options)); // (1)-
Affiche
thom4.net/– les identifiants, l’ancre et les arguments ont été retirés par la fonctionformat().
Le constructeur URL accepte une URL de référence en second argument.
Cette adresse résout un chemin absolu à partir du premier argument :
const url1 = new URL('/v1/', 'https://apprendre-nodejs.fr');
const url2 = new URL('../', 'https://apprendre-nodejs.fr/v1/');
console.log(url1.toString()); // (1)
console.log(url2.toString()); // (2)-
Affiche
apprendre-nodejs.fr/v1/. -
Affiche
thom4.net/.
url.parse()
|
Transforme une chaîne de caractères en un objet utilisable avec la fonction
|
classe URL
|
Représentation de la structure d’une URL. |
classe URLSearchParams
|
Représentation des paramètres d’URL. |
URL
url.format()
|
Transforme un objet |
url.toString()
|
Transforme l’objet |
attribut url.hash
|
Fragment de l’URL. |
attribut url.hostname
|
Nom de l’hôte. |
attribut url.pathname
|
Chemin d’accès à la ressource. |
attribut url.protocol
|
Protocole spécifié. |
attribut url.search
|
Paramètres de l’URL, caractère |
attribut url.searchParams
|
Objet permettant de manipuler les paramètres. Voir ci-après. |
Manipuler une URL est plus aisé lorsqu’elle est structurée sous forme d’objet.
Les paramètres ne sont pas en reste avec l’attribut searchParams :
const example = new URL('https://thom4.net/');
example.searchParams.set('search', 'node.js');
console.log(example.toString()); // (1)
console.log(example.searchParams.toString()); // (2)
example.searchParams.delete('search');
console.log(example.toString()); // (3)-
Affiche
thom4.net/?search=node.js– représentation de l’URL complète. -
Affiche
search=node.js– représentation des paramètres seulement. -
Affiche
thom4.net/– le paramètresearchet sa valeur ont été supprimés de l’URL.
URLSearchParams
searchParams.append()
|
Ajoute un paramètre à la suite de l’URL. Cette fonction permet d’ajouter plusieurs fois une même clé, peu importe sa valeur. |
searchParams.delete()
|
Supprime un paramètre d’URL. |
searchParams.get()
|
Retoure la valeur d’un paramètre donné. |
searchParams.getAll()
|
Renvoie toutes les valeurs d’un paramètre donné. |
searchParams.has()
|
Indique |
searchParams.set()
|
Affecte une valeur à un paramètre d’URL. |
searchParams.toString()
|
Retourne une représentation de l’objet sous forme d’une chaîne de caractères exploitable dans une URL. |
|
💬
|
Documentation Module url
La documentation du module |
6.4. fs : manipuler le système de fichiers
Le module fs est un incontournable.
On y a recours dès que l’on a besoin de lire ou d’écrire dans un fichier.
On s’en sert également pour créer, déplacer ou supprimer des fichiers
et des répertoires.
const fs = require('fs');
const path = require('path');
const filename = path.join(__dirname, 'package.json');
fs.readFile(filename, (err, content) => { // (1)
console.log(String(content)); // (2)
});-
Lorsque la lecture du fichier aboutit, la fonction de rappel est appelée avec deux paramètres : un objet d’erreur et le contenu.
-
Affiche le contenu d’un fichier
package.json.
|
💡
|
Raccourci Variables __filename et __dirname
dirname-filename.js
Ces variables sont utiles pour opérer sur des chemins relatifs au fichier actuel. |
Dans l’exemple précédent, nous avons parcouru le contenu d’un fichier.
fs.readdir() parcourt un répertoire :
const {readdir} = require('fs');
readdir('.', (error, files) => console.log(files));En l’exécutant, nous obtenons le résultat suivant :
node fs/ls.js [ '.eslintrc.yaml', 'console', 'debug.txt', 'deprecation-warning.js', 'process/env.js', ... 'util' ]
Dans les environnements UNIX, le point (.) pour faire référence au
répertoire courant et deux points (..) pour le répertoire parent.
C’est le cas avec Node également.
La notion de courant fait référence à l’emplacement depuis lequel nous
appelons l’exécutable node.
Changeons de répertoire :
cd ../.. node chapter-04/examples/fs/ls.js [ '.eslintignore', 'README.md', 'chapter-01' 'chapter-02' ... 'tests' ]
Les chemins relatifs se définissent par rapport à l’emplacement depuis
lequel on exécute la commande node.
__dirname et __filename sont déterminées par rapport
à l’emplacement du script qui fait référence à ces variables.
Puisque les opérations liées au système de fichiers ne sont pas immédiates les fonctions de ce module sont en majorité asynchrones. Leur rapidité d’exécution varie en fonction du support de stockage utilisé (disque, mémoire), de son usure et de la capacité de traitement de la CPU de l’ordinateur.
Cela veut aussi dire que les erreurs sont obtenues de manière asynchrone :
const fs = require('fs');
fs.rmdir(__dirname, (error) => {
console.error(error.message); // (1)
});-
Indique que la suppression n’a pas abouti car le répertoire en question n’est pas vide – et pour cause, c’est celui qui contient notre fichier d’exemple.
On peut articuler plusieurs opérations entre elles et utiliser le module path
pour construire des chemins robustes qui fonctionnent avec tous les systèmes
d’exploitation, sans effort.
L’exemple suivant crée un répertoire dans un dossier temporaire, copie un fichier sous un autre nom et liste le contenu du répertoire une fois la copie effectuée.
const {tmpdir} = require('os');
const {join} = require('path');
const fs = require('fs');
const dest_dir = join(tmpdir(), 'test'); // (1)
fs.mkdir(dest_dir, (error) => { // (2)
const dest = join(dest_dir, 'example-copy.js');
fs.copyFile(__filename, dest, (error) => { // (3)
if (error === null) {
console.log(`La copie vers ${dest} s'est bien passée.`);
}
});
});-
On assemble un chemin composé à partir du répertoire temporaire fourni par le système d’exploitation.
-
Crée le répertoire en question.
-
Copie le contenu de ce script d’exemple vers le répertoire en question en lui attribuant un nouveau nom.
|
🚨
|
Sécurité Utilisateur et permissions
Le script Node exécuté a le droit d’accéder, d’altérer et de supprimer au même titre que l’utilisateur système qui lance le script. Ce n’est pas grave si on exécute du code écrit soi-même. Il faut être vigilant·e si le code exécuté provient d’une autre personne. |
Si l’exemple précédent semble agréable à lire, il révèle deux points de vigilance.
J’ai écrit le code de manière "optimiste", pour des questions de lisibilité.
Pourtant, à chaque opération, il y a une possibilité d’erreur à gérer :
de la création du répertoire jusqu’à la lecture des fichiers qu’il contient.
Il faudrait vérifier l’argument error à chaque fois et décider quoi faire
en fonction de la nature du problème.
Je vous invite à modifier ce code
pour afficher la valeur des variables error à l’aide des
fonctions du module console.
Certaines erreurs apparaissent quand nous invoquons le script une seconde fois.
L’imbrication des fonctions de rappel fait qu’il est
difficile d’en interrompre la suite.
Une bonne piste serait d’appliquer l'utilitaire promisify
sur les fonctions du module fs afin de créer une
chaîne de promesses.
Nous apprendrons à le faire dans la section sur le module util.
fs.appendFile()
|
Ajoute un contenu à la suite d’un fichier existant. Le fichier sera créé le cas échéant. |
fs.copyFile()
|
Copie un fichier depuis un emplacement vers un autre. |
fs.mkdir()
|
Crée un nouveau répertoire. Le répertoire parent doit déjà exister. |
fs.readdir()
|
Obtient la liste des fichiers et dossiers contenus dans un répertoire donné. |
fs.readFile()
|
Lit le contenu d’un fichier. |
fs.rename()
|
Renomme un fichier ou un répertoire. |
fs.rmdir()
|
Supprime un répertoire. Il doit être vide. |
fs.stat()
|
Retourne des informations à propos d’un chemin d’accès : est-ce que c’est un fichier, un répertoire, un lecteur, un lien symbolique ? Des attributs précisent la taille du fichier (en octets), l’identifiant système de son propriétaire, la date de création/modification/dernier accès, etc. |
fs.symlink()
|
Crée un lien symbolique vers un emplacement. |
fs.truncate()
|
Raccourcit le contenu d’un fichier à une longueur donnée (en nombre d’octets). Si aucun argument n’est donné, le contenu du fichier est remis à zéro. |
fs.createReadStream()
|
Crée un flux de lecture, pour lire un fichier en continu. |
fs.createWriteStream()
|
Crée un flux d’écriture, pour écrire en continu dans un fichier. |
|
💬
|
Définition Lien symbolique
Fichier qui fait référence à un autre fichier – c’est comme un alias. Toutes les modifications effectuées sur le lien symbolique sont répercutées sur le fichier d’origine. |
|
💬
|
Documentation Module fs
La documentation du module |
6.5. events : programmer des événements
Le module events contient le nécessaire pour créer du code communiquant
à l’aide de fonctions d’écoute et d’émission de messages.
C’est comme un centre de tri postal, mais avec des variables
en guise de courriers.
const EventEmitter = require('events');
const emitter = new EventEmitter(); // (1)
emitter.on('date', (date) => { // (2)
console.log('Année : %d', date.getFullYear());
});
emitter.emit('date', new Date('2018-03-01')); // (3)
emitter.emit('date', new Date('1983-03-24'));-
Création d’un gestionnaire d’événements.
-
Enregistrement d’une fonction d’écoute – elle sera exécutée à chaque émission de l’événement
date. -
Émission d’un événement
date, avec comme argument, un objetDate.
Un événement se décompose en trois parties : les fonctions d’écoute,
les émissions de message et un objet EventEmitter
qui fait le lien entre les deux.
|
💬
|
Langage ECMAScript n’est pas événementiel
Contrairement à ce que l’on pourrait penser, le langage ECMAScript ne possède aucune structure de gestion d’événements. S’il est possible de réagir à des événements dans les navigateurs web, c’est grâce à la spécification DOM – l’API JavaScript pour manipuler une structure de document HTML. |
On peut décider d’écouter un événement une seule fois avec once().
const EventEmitter = require('events');
const emitter = new EventEmitter();
emitter.once('date', (date) => { // (1)
console.log('Année : %d', date.getFullYear());
});
emitter.emit('date', new Date('2018-03-01'));
emitter.emit('date', new Date('1983-03-24'));-
Bien que l’événement
datesoit appelé deux fois, la fonction d’écoute ne réagira qu’une seule fois.
La fonction removeListener() débranche une fonction d’écoute selon
les critères de notre choix :
const EventEmitter = require('events');
const emitter = new EventEmitter();
const tick = () => process.stdout.write('.');
let counter = 0;
setInterval(() => {
counter++;
emitter.emit('date', new Date()); // (1)
if (counter === 5) {
process.exit(0);
}
}, 1000);
emitter.on('date', tick); // (2)
emitter.on('date', () => {
if (counter === 3) {
emitter.removeListener('date', tick); // (3)
}
});-
L’événement
dateest émis toutes les secondes. -
La fonction
tickest appelée toutes les secondes. -
La fonction
tickest débranchée de l’événementdateau bout de trois incréments.
On remarquera qu’il faut pouvoir faire référence à la fonction d’écoute afin de la débrancher.
Une utilisation alternative des événements consiste à étendre la classe EventEmitter.
Une fois étendue, notre nouvelle classe bénéficiera des méthodes .on() etc.
const EventEmitter = require('events');
class Car extends EventEmitter { // (1)
constructor (name) {
super(); // (2)
this.name = name;
}
start () {
this.emit('action', this, 'démarrer'); // (3)
}
}
const auto = new Car('Boombo');
auto.on('action', (car, action) => { // (4)
console.log('%s est en train de %s', car.name, action);
});
auto.start();-
Extension de la classe
EventEmitter. -
L’utilisation de la fonction spéciale
super()est indispensable. Elle revient à invoquernew EventEmitter()par mécanisme de cascade. -
La méthode
.start()encapsule un appel à la méthode.emit(). -
La fonction réagira à l’émission de l’événement
actionquand la méthode.start()sera appelée.
Ce mécanisme est utile pour cacher de la complexité applicative, pour exécuter une fonction plusieurs fois lors d’un événement donné, pour exposer une surface d’action compréhensible, tout en rendant notre code communiquant vers l’extérieur.
Plusieurs modules Node utilisent les événements pour nous permettre d’y
réagir de manière totalement optionnelle.
Tout ce que l’on vient d’expliquer s’applique à l’identique aux modules
process, child_process et http.
EventEmitter
on()
|
Enregistre une nouvelle fonction réagissant à un événement donné. |
once()
|
Enregistre une nouvelle fonction réagissant une seule fois à un événement donné. |
emit()
|
Émet un événement. Si des arguments additonnels sont présents, ils sont transmis aux fonctions écoutant cet événement. |
eventNames()
|
Liste les événements pour lesquels on a enregistré au moins une fonction d’écoute. |
listeners()
|
Liste les fonctions écoutant les événements. |
removeListener()
|
Supprime une fonction d’écoute d’un événement donné. |
removeAllListeners()
|
Supprime toutes les fonctions d’écoute d’un événement donné. |
setMaxListeners()
|
Change le nombre maximum de fonctions d’écoute possibles (10 par défaut, c’est peu). |
|
💬
|
Documentation Module events
La documentation du module |
6.6. util : transformer des fonctions de rappel en promesses
Le petit module util contient des fonctions utilitaires
qui n’entreraient pas dans le périmètre d’autres modules.
On y trouve util.format(), une fonction qui fait beaucoup penser à
console.log() mais sans afficher le message :
const {format} = require('util');
const message = format( // (1)
'Il fait %s aujourd\'hui',
'☀️ '
);
// console.log(message);-
Affecte le message formaté à une variable sans l’afficher.
Pour afficher la valeur de la variable message de l’exemple précédent,
il suffirait de décommenter la dernière ligne et de (re)lancer le script.
La fonction util.debuglog() formate aussi des messages.
Son affichage est toutefois conditionnel, ce qui est pratique quand on veut
déboguer des variables sans toucher au code entre deux exécutions.
const {debuglog} = require('util');
const {cpus} = require('os');
const debug = debuglog('nodebook'); // (1)
const infos = cpus().map(cpu => cpu.model);
console.log('Cet ordinateur a %d CPU.', infos.length); // (2)
debug('Le modèle de CPU est %s.', infos[0]); // (3)-
Création d’un débogueur nommé
nodebook. -
Ce message s’affiche systématiquement quand on exécute le script.
-
Le modèle de CPU sera affiché en invoquant Node en présence de la variable d’environnement
NODE_DEBUG.
En lançant la commande suivante, seul le message de console.log() s’affiche :
node util/debuglog.js Cet ordinateur a 4 CPU.
Il nous faut alors utiliser la variable d’environnement NODE_DEBUG.
En lui attribuant la même valeur que notre débogueur, celui-ci affichera alors
le contenu attendu :
NODE_DEBUG=nodebook node util/debuglog.js Cet ordinateur a 4 CPU. NODEBOOK 32486: Le modèle de CPU est Intel(R) Core(TM) i5-6267U CPU @ 2.90GHz.
Si l’on souhaite avoir plusieurs débogueurs, dans un ou plusieurs script(s),
il suffit de séparer leurs noms par des virgules
(ex: NODE_DEBUG=nodebook,test,fromage).
Une de mes fonctions préférées est util.promisify().
Elle convertit une fonction acceptant un callback en une fonction
retournant une promesse.
C’est particulièrement pratique quand on n’a pas la maîtrise du
code source original.
const {promisify} = require('util');
const readdir = promisify(require('fs').readdir); // (1)
readdir(__dirname) // (2)
.then((files) => console.log(files)) // (3)
.catch((error) => console.error(error.message));-
Affecte une version transformée de
fs.readdir()grâce àutil.promisify(). -
On ne passe pas de fonction de rappel contrairement à
fs.readdir(). -
Le résultat de l’opération est passé à la résolution de promesse.
Cela ne paraît pas important mais cela ouvre un potentiel de simplification
énorme pour nous.
Fini l’argument error qui nous embête : on peut le collecter quand cela
nous arrange grâce à .catch().
Cela limite également le nombre de lignes de code à écrire pour arriver au même résultat :
const fs = require('fs');
const readdir = (path) => {
return new Promise((resolve, reject) => {
fs.readdir(path, (error, files) => {
error ? reject(error) : resolve(files);
});
});
};
readdir(__dirname)
.then((files) => console.log(files))
.catch((error) => console.error(error.message));
util.debuglog()
|
Crée une fonction de débogage similaire à |
util.deprecate()
|
Affiche un message d’avertissement lorsque vous souhaitez retirer une fonction partagée dans une version ultérieure de votre code. |
util.format()
|
Retourne une chaîne de caractères formatée, comme |
util.promisify()
|
Transforme une fonction de rappel en promesse. |
|
💬
|
Documentation Module util
La documentation du module |
6.7. http : créer et interroger des ressources via le protocole HTTP
Le module http est un incontournable de Node.
Il a deux facettes : la création de requêtes et celle de serveurs.
Dans le premier cas, on utilise le protocole HTTP pour accéder à une ressource distante
et recevoir une réponse.
Dans le second, on utilise le protocole HTTP pour
mettre à disposition des ressources et les envoyer en réponse.
Le module https offre exactement les mêmes propriétés.
Il est à privilégier pour établir des connexions sécurisées
vers des adresses commençant par https://.
const {get} = require('https');
const url = 'https://apprendre-nodejs.fr/v1/package.json';
get(url, (response) => { // (1)
response.on('data', (data) => {
console.log(data.toString()); // (2)
});
});-
Initialisation de la requête – un objet représentant la réponse du serveur distant nous est transmis. À ce stade-là, le serveur n’a pas encore commencé à renvoyer des données.
-
On en est à l’étape où on reçoit des données. Le contenu du fichier
package.jsonest affiché sous forme de chaînes de caractères.
Ce premier exemple met en lumière la nature asynchrone et non-bloquante par défaut de Node. La création d’une requête et l’obtention de la réponse sont séparées d’un délai variable, pendant lequel Node ne bloque pas le reste du code. Les fonctions de rappel sont appelées lorsque l’action est terminée.
En regardant le code de l’exemple précédent, on en apprend un peu plus sur le fonctionnement d’une requête HTTP :
-
Envoi de la requête au serveur distant :
get(). -
Obtention d’une réponse : objet
responsedans la fonction de rappel. -
Transmission d’informations : événement
data. -
Clôture de la transmission : événement
end– voir exemple suivant.
Pour rester rapide, Node fait aussi le choix de transmettre les données
au fur et à mesure.
L'événement data renvoie en réalité environ 10 Ko de données.
L’exemple précédent a tout renvoyé d’un coup car le volume des données
était inférieur à 10 Ko.
Voyons maintenant ce qui se passe lorsqu’on fait appel à un fichier plus volumineux :
const {get} = require('https');
let count = 0;
get('https://apprendre-nodejs.fr/v1/index.html', response => {
response.on('data', (data) => {
count = count + 1;
const ko = data.length/1024;
console.log('Morceau #%d : %iKo', count, ko); // (1)
});
response.on('end', () => { // (2)
console.log('Fini (%d morceaux)', count); // (3)
});
});-
Affiche ce message à chaque morceau/paquet reçu.
-
L’événement
endse déclenche lorsque la requête n’a plus de données à recevoir. -
Affiche le nombre de morceaux reçus pour obtenir une réponse complète.
|
💡
|
Pratique Paramètre URL
Les fonctions Il est aussi possible de leur passer un objet URL. C’est plus pratique si vous manipulez des URL complexes ou si vous paginez. |
En clair, on peut recevoir une réponse en plusieurs fois, petit bout par petit bout.
Les données reçues ne sont pas forcément complètes.
Cela pose problème à des fonctions comme
JSON.parse(), qui nécessitent un document
JSON complet pour produire un résultat.
Une solution consiste à accumuler les morceaux de réponse et à les assembler. Cela veut aussi dire que l’on consomme autant de mémoire que l’on reçoit de données.
Une autre solution repose sur l’utilisation des flux de données.
Ils pompent et brassent les données comme du liquide, en consommant peu de mémoire.
On en parle plus loin, dans la section sur le module stream.
http.createServer()
|
Initialise un serveur HTTP et fournit une boîte à outils pour
gérer les connexions entrantes via |
http.get()
|
Crée une connexion HTTP de type |
http.request()
|
Crée une connexion HTTP du type de son choix : |
La fonction http.request() gère une requête plus finement.
On peut aisément régler les en-têtes, le verbe HTTP et les modalités de
transmission des données.
L’exemple suivant illustre l’envoi d’une requête HEAD.
Ce verbe HTTP indique au serveur distant de répondre avec les métadonnées
de la ressource, mais sans les données (response.on('data')) :
const https = require('https');
const options = { // (1)
protocol: 'https:',
host: 'apprendre-nodejs.fr',
path: '/v1/package.json',
method: 'HEAD',
};
const request = https.request(options);
request.setHeader('Accept', 'application/json'); // (2)
request.end(); // (3)
request.on('response', (response) => {
const lastModified = response.headers['last-modified'];
console.log('Modifié le %s', lastModified); // (4)
});-
Construction des paramètres de requête pour
http.request(). -
Explicite au serveur distant la nature du contenu que l’on s’apprête à recevoir.
-
Déclenche l’envoi de la requête sur le réseau.
-
Affiche la date de modification de la ressource distante.
|
💬
|
Avancé Parser, destructurer, combiner
La fonction http/request-advanced.js
const https = require('https');
const {parse} = require('url');
const url = 'https://apprendre-nodejs.fr/v1/package.json';
const parsedUrl = parse(url);
|
L’utilisation de http.get() et http.request() est simple tant qu’on évite
la personnalisation de la requête.
On ajoute progressivement de plus en plus de travail pour bien envoyer une
requête, collecter les données et gérer les erreurs.
Nous verrons comment arriver au même résultat en écrivant moins de code grâce aux
modules npm
(chapitre 5).
http.ClientRequest
request.on('response')
|
Se déclenche lorsque la ressource distante a accepté la requête et s’apprête à nous transmettre les données. |
request.on('end')
|
Se déclenche lorsque la ressource distante a signalé ne plus avoir de données à nous transmettre. |
request.end()
|
Termine l’initialisation et entame la connexion vers la ressource distante.
Dans le cas d’une requête |
request.getHeader()
|
Retourne la valeur d’un en-tête de requête. |
request.setHeader()
|
Change la valeur d’un en-tête de requête.
C’est une pratique courante pour préciser nos intentions auprès du serveur
distant : format de fichier réponse attendu ( |
request.setTimeout()
|
Définit un chronomètre pour déclarer la requête en erreur si aucune réponse n’a été obtenue dans ce délai imparti. |
request.write()
|
Transmet un morceau de contenu vers la ressource distante. Cette méthode s’utilise lorsque l’on effectue un téléversement progressif. |
http.IncomingMessage
message.on('data')
|
Se déclenche quand un morceau de données est obtenu par le client. |
message.on('end')
|
Se déclenche quand nous avons obtenu toutes les données émises par le serveur. |
message.on('readable')
|
Se déclenche quand nous pouvons commencer à lire les données. |
message.read()
|
Obtient un morceau de données manuellement – au lieu d’utiliser
l’événement |
message.destroy()
|
Termine la transmission des données sans que le serveur distant nous aie tout transmis. |
Attribut message.headers
|
Objet contenant les en-têtes de la réponse – le serveur distant décide de leur contenu. |
Attribut message.statusCode
|
Code qui reflète l’état de compréhension de notre requête par le serveur distant.
|
Il est temps de nous pencher sur l’autre versant du module : la création d’un serveur HTTP.
const http = require('http');
const server = http.createServer();
server.listen(4000, 'localhost'); // (1)
server.on('listening', () => { // (2)
console.log('Serveur démarré !');
});
server.on('request', (request, response) => {
const {method, url} = request;
console.log('URL demandée : %s %s', method, url); // (3)
response.end('Coucou'); // (4)
});-
Ouverture de l’acceptation des connexions réseau sur le port
4000, uniquement sur la boucle locale (localhost) – une erreur sera affichée si ce port réseau est déjà pris par un autre processus. -
Affiche
Serveur démarré !quand Node a fini de négocier l’accès aux ressources réseau avec le système d’exploitation – à ce stade, le serveur est prêt à recevoir des connexions entrantes. -
Lorsqu’une requête arrive, affiche l’URL demandée par le client.
-
Termine la connexion avec le client – ce dernier considère sa requête comme terminée.
|
💬
|
Aparté Pourquoi démarrer un serveur HTTP ?
Ce concept peut sembler étrange lorsqu’on vient d’un autre langage de programmation. Après tout, Apache ou nginx s’en chargent très bien pour nous. Un serveur HTTP embarqué avec Node, c’est avant tout une question d’autonomie et d’interopérabilité. Il n’y a pas besoin de module spécial pour Apache ni pour nginx. On peut développer un site web et le faire fonctionner instantanément sans installer autre chose. L’intégration avec un serveur Apache, nginx ou autre nécessite ensuite très peu d’efforts. |
Le serveur se démarre de la même manière qu’un script ordinaire :
node http/server.js Serveur démarré !
Le serveur continuera d’accepter les requêtes entrantes jusqu’à ce que le processus soit interrompu par une erreur ou par un signal d’arrêt – en utilisant la combinaison de touches Ctrl+C par exemple.
Accédez au serveur HTTP en ouvrant un navigateur web comme Firefox ou Chrome
puis en inscrivant localhost:4000 dans la barre d’adresses.
Dirigez ensuite le navigateur vers localhost:4000/test et observez les
changements.
|
💡
|
Pratique Parler au serveur depuis le terminal
La commande Unix curl -i http://localhost:4000/test curl -i -XHEAD http://localhost:4000/test L’option |
On a posé les bases d’un serveur HTTP minimaliste sur lequel on pourra construire pas à pas tout type d’application web. Que manque-t-il pour en faire un serveur web ? Il faut encore typer les ressources renvoyées afin qu’elles soient comprises par un navigateur, c’est-à-dire signaler que nos réponses contiennent du HTML, du CSS, des images, etc.
Modifions notre exemple précédent pour renvoyer du HTML :
const http = require('http');
const server = http.createServer();
server.listen(4000, 'localhost');
server.on('request', (request, response) => {
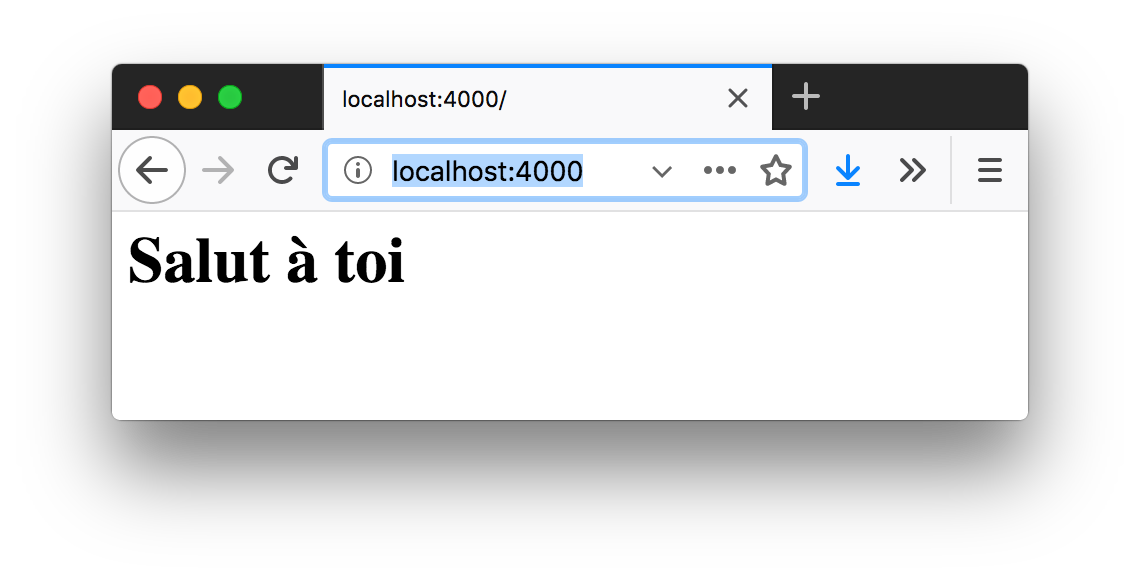
response.write('<h1>Salut à toi</h1>');
response.end();
});|
🚨
|
Important La fonction
response.end()L’appel de la fonction Si on supprime l’appel à |
Dirigeons notre navigateur vers localhost:4000 pour observer
le résultat.
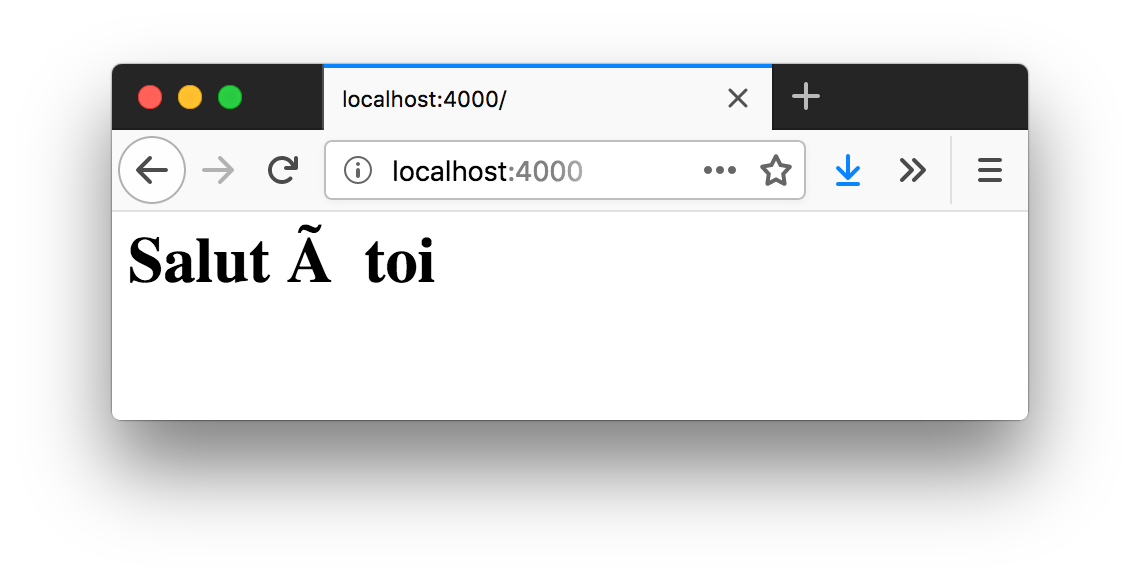
http/web-server.jsLa balise HTML <h1> a bien été prise en compte, mais le
caractère à n’a pas été compris par le navigateur, qui affiche à .
Si le serveur distant ne précise pas l’encodage des caractères, le navigateur l’interprète en ASCII. Or, les éditeurs de code enregistrent les fichiers avec un autre encodage : UTF-8. Ce standard englobe les alphabets du monde entier, dont les accents et signes diacritiques de la langue française.
|
💬
|
Histoire American Standard Code for Information Interchange (ASCII)
Au début de l’informatique contemporaire, les systèmes étaient conçus pour comprendre l’alphabet anglais, les signes de ponctuations et des caractères spéciaux. On parle alors de standard d’encodage ASCII. L’émergence d’Internet et du World Wide Web ont popularisé l’encodage UTF-8 afin d’exprimer de manière commune les caractères spéciaux de toutes les langues du monde entier. |
Pour indiquer aux navigateurs web quel est l’encodage utilisé,
le protocole HTTP dispose de l’en-tête Content-Type :
const http = require('http');
const server = http.createServer();
server.listen(4000, 'localhost');
server.on('request', (request, response) => {
const content_type = 'text/html; charset=utf-8';
response.setHeader('Content-Type', content_type); // (1)
response.write('<h1>Salut à toi</h1>');
response.end();
});-
L’en-tête HTTP
Content-Typeindique explicitement que le contenu transféré est du HTML, encodé en UTF-8.
Cette indication suffit au navigateur pour décoder les caractères et les afficher comme on l’espérait.
http/web-server-ok.jsL’étape suivante consisterait à transmettre deux contenus différents selon l’URL demandée, par exemple, une page HTML et un fichier CSS pour l’habiller.
const http = require('http');
const server = http.createServer();
server.listen(4000, 'localhost');
server.on('request', (request, response) => {
if (request.url === '/main.css') { // (1)
response.setHeader('Content-Type', 'text/css'); // (2)
response.write('body{ font-size: 18px; color: blue; }');
response.end();
}
else {
const content_type = 'text/html; charset=utf-8';
response.setHeader('Content-Type', content_type);
response.write('<link rel="stylesheet" href="/main.css">');
response.end('<h1>Salut à toi</h1>');
}
});-
Si la requête entrante indique
/main.csscomme chemin, alors on lui renvoie du contenu interprétable comme du CSS. -
On indique au client que ce contenu est du texte contenant une feuille de styles CSS.
Si tout se passe bien, le chargement de la page HTML devrait déclencher
une requête vers localhost:4000/main.css.
Nous en avons la confirmation visuelle en visitant le serveur grâce à un
navigateur web :
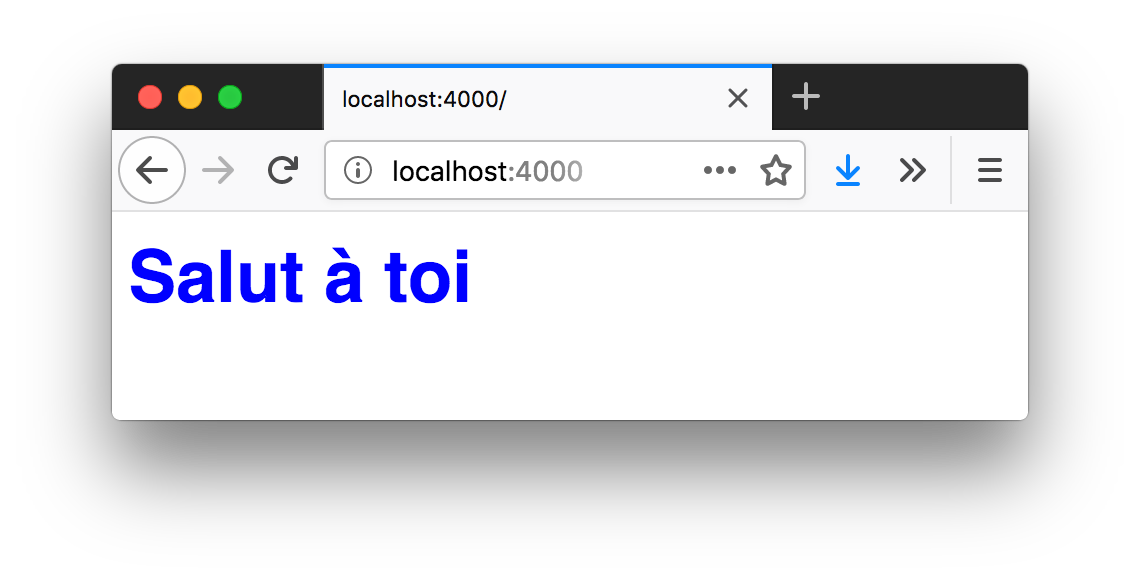
http/web-server-routes.jsOn est en situation de contrôle : on décide de ce qu’on répond. C’est une manière d’apprendre petit à petit comment fonctionne le protocole HTTP sur lequel repose une majorité de notre activité sur Internet.
On a couvert les principes du module http, mais il reste beaucoup de choses
à apprendre pour développer une application web maintenable.
Ce sera le sujet du chapitre 7,
aidé par les modules npm que l’on apprendra
à manipuler dans le chapitre 5.
http.Server et de https.Server
server.close()
|
Arrête l’écoute de nouvelles connexions. Les connexions existantes sont maintenues jusqu’à ce qu’elles soient honorées. |
server.listen()
|
Démarre l’acceptation des connexions sur un port et une adresse donnés.
Combinée avec |
server.on('close')
|
Se déclenche lorsque le serveur s’arrête et a terminé d’honorer toutes les connexions déjà ouvertes. |
server.on('connection')
|
Se déclenche lorsqu’une nouvelle connexion réseau est établie. |
server.on('request')
|
Se déclenche lorsqu’une nouvelle requête entrante est adressée au serveur. |
server.on('upgrade')
|
Se déclenche lorsqu’une requête entrante demande un changement de protocole. Utilisée pour basculer vers HTTP/2 et WebSocket. |
response.on('close')
|
Se délenche lorsque la requête a été terminée par le client, avant qu’on ait pu transmettre l’intégralité des données. |
response.on('finish')
|
Se délenche après l’envoi du dernier morceau de données. |
response.end()
|
Signale au client que nous n’avons plus de données à transmettre. |
response.getHeader()
|
Retourne la valeur d’un en-tête de la réponse. |
response.removeHeader()
|
Supprime un en-tête de la réponse. |
response.setHeader()
|
Affecte une valeur à un en-tête de la réponse. |
response.write()
|
Transmet un morceau de données au client. |
response.writeHead()
|
Transmet le code de réponse et un ensemble d’en-têtes au client. |
Attribut response.statusCode
|
Contient le code de réponse qui sera transmis au client. |
|
💬
|
Documentation Module http
La documentation du module |
6.8. os : en savoir plus sur les capacités de l’ordinateur
Le module os donne des informations sur l’environnement système dans lequel
le script est exécuté.
Cela permet par exemple de prendre des décisions par rapport aux ressources disponibles
(mémoire, CPU, réseau) et par rapport au système d’exploitation (Windows, Linux, macOS).
const os = require('os');
const {username} = os.userInfo();
const cpus = os.cpus().length;
console.log(
`Salut ${username}, cet ordinateur a ${cpus} CPU.` // (1)
);-
Affiche un message comme
Salut anonymous, cet ordinateur a 4 CPU.
Node a pour vocation de nous abstraire du système d’exploitation en faisant en sorte que notre code fonctionne partout de la même façon. Pourtant, des situations nous obligent à prendre en compte certains critères pour déterminer un choix.
Par exemple, lister les applications installées sur l’ordinateur dépend du système ; leur emplacement d’installation est différent sous Linux, Windows et macOS.
const {type} = require('os');
const {readdir} = require('fs');
const log = (error, modules) => {
return error
? console.error(error.message)
: console.log(modules);
};
switch (type()) {
case 'Windows_NT': readdir('C:\\Program Files', log); break;
case 'Linux': readdir('/usr/bin', log); break;
case 'Darwin': readdir('/Applications', log); break;
}L’exemple précédent se base sur la valeur retournée par la fonction os.type()
afin de choisir le répertoire à lister.
On pourrait combiner ce mécanisme avec le module child_process,
pour appeler une application système différente et parvenir à un résultat similaire.
À l’inverse, on peut accéder à une ressource de manière uniforme, peu importe
le nom du compte utilisateur ou du type de système d’exploitation.
Nous allons maintenant lire le contenu du fichier .npmrc,
le fichier de configuration de
l'exécutable npm :
const {homedir} = require('os');
const {readFile} = require('fs');
const {join} = require('path');
const file = join(homedir(), '.npmrc'); // (1)
readFile(file, (error, content='') => {
if (error && error.code !== 'ENOENT') { // (2)
return console.log(error);
}
console.log(String(content));
});-
Construit un chemin sans connaissance préalable du système d’exploitation sur lequel tournera le script : par exemple
C:\Users\anonymous\.npmrcpour Windows,/Users/anonymous/.npmrcpour macOS et/home/anonymous/.npmrcpour Linux. -
ENOENTest un code d’erreur indiquant que le fichier n’existe pas ; on se permet de l’ignorer et de considérer que le fichier est vide.
os.arch()
|
Retourne l’architecture CPU.
Les valeurs les plus courantes sont généralement |
os.cpus()
|
Retourne un tableau contenant des informations à propos de la ou des CPU. Entre autres, on retrouve leur modèle, leur fréquence et le temps passé en attente ou en action depuis le démarrage de l’ordinateur. |
os.homedir()
|
Retourne le chemin vers le répertoire utilisateur.
Équivalent de la variable |
os.hostname()
|
Retourne l’identifiant réseau de la machine. |
os.networkInterfaces()
|
Retourne un tableau contenant des informations à propos de la ou des carte(s) réseau de l’ordinateur. Entre autres, on retrouve l’adresse IP (IPv4, IPv6), l’adresse MAC et le masque réseau. |
os.platform()
|
Retourne la nature du système d’exploitation.
Les valeurs les plus courantes sont généralement |
os.tmpdir()
|
Retourne l’emplacement du répertoire temporaire fourni par le système d’exploitation. |
os.type()
|
Retourne une forme normalisée de la nature du système d’exploitation,
équivalent à ce que retournerait la commande Unix |
Attribut os.constants
|
Objet contenant la liste des signaux système et des codes d’erreur. |
Attribut os.EOL
|
Caractère utilisé pour marquer les fins de ligne.
En général le caractère |
|
💬
|
Documentation Module os
La documentation du module |
6.9. child_process : appeler un exécutable système
Le module child_process exécute des programmes externes,
leur transmet des données et consulte leurs résultats via
les flux standards.
const {exec} = require('child_process');
exec('npm --version', (error, stdout, stderr) => { // (1)
console.log(`npm version ${stdout.trim()}`); // (2)
});-
Exécute la commande exécute la fonction de rappel, avec comme arguments la sortie standard et la sortie erreur du processus enfant.
-
Affiche
npm version 6.4.0.
L’utilisation du module child_process se justifie quand un programme
externe fournit une fonctionnalité mais ne s’interface pas avec Node,
ou encore quand on veut sortir l’exécution d’un script Node du processus courant
pour tirer parti des autres CPU de l’ordinateur sans ralentir l’application principale.
La fonction child_process.exec() accepte un deuxième argument optionnel.
cwd (current working directory) en est une des options utiles.
const {exec} = require('child_process');
exec('ls .', {cwd: null}, (error, stdout, stderr) => { // (1)
console.log(stdout);
});-
On lance la commande système
lssans spécifier le répertoire de travail.
Exécutons le script pour observer le résultat :
node child_process/ls.js
Le constat est similaire à celui produit avec le module fs :
les fichiers listés sont ceux du répertoire courant,
notre emplacement dans le terminal.
Modifions maintenant la valeur de l’option cwd.
const {exec} = require('child_process');
exec('ls .', {cwd: '/'}, (error, stdout, stderr) => { // (1)
console.log(stdout);
});-
La valeur de
cwdest réglée sur/, c’est-à-dire le répertoire racine du système de fichiers.
node child_process/ls-root.js
La liste des fichiers et répertoires affichés est désormais différente,
même si la commande passée à child_process.exec() est la même.
cwd a changé le répertoire courant l’espace d’une commande.
|
💬
|
Performance ls vs. fs.readdir
Si on arrive au même résultat avec
|
env est une deuxième option à passer à child_process.exec().
Elle redéfinit les variables d’environnement utilisables
par le processus enfant :
const {exec} = require('child_process');
const env = {PING_COUNT: 1, ...process.env}; // (1)
const cmd = 'ping -c $PING_COUNT thom4.net';
exec(cmd, {env}, (error, stdout) => { // (2)
return error
? console.error(error)
: console.log(stdout);
});-
On transmet les variables d’environnement existantes au processus enfant.
-
Utilisation de la variable d’environnement
PING_COUNTcomme valeur d’option du programmeping.
Si on ne transmettait pas les valeurs de process.env au processus enfant,
la variable d’environnement PATH ne serait pas définie.
Le processus enfant ne saurait plus où chercher l’exécutable ping.
On aurait pu appeler le programme ping en utilisant un chemin absolu comme
/sbin/ping mais son emplacement varie selon les systèmes d’exploitation.
node child_process/ping.js PING thom4.net (185.31.40.11): 56 data bytes 64 bytes from 185.31.40.11: icmp_seq=0 ttl=56 time=23.763 ms --- thom4.net ping statistics --- 1 packets transmitted, 1 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 23.763/23.763/23.763/0.000 ms
|
🚨
|
Compatibilité Mon programme ne fonctionne pas sous Windows/Linux/macOS
Le programme externe peut ne pas exister sur tous les systèmes d’exploitation, ou ne pas s’appeler avec les mêmes arguments, ni avec le même nom. Une des solutions consiste à se reposer sur le module |
child_process.spawn() est une autre approche de démarrage
et de communication avec un processus externe.
const {spawn} = require('child_process');
const subprocess = spawn('cat', ['package.json']); // (1)
subprocess.stdout.on('data', (data) => { // (2)
console.log(String(data)); // (3)
});-
catest un programme qui affiche le contenu d’un fichier – un peu commefs.readFile. -
Les données retournées par la commande externe se lisent depuis les flux de sortie.
-
Affiche le contenu du fichier
package.json.
Les arguments et options à transmettre au programme sont passés dans un tableau.
Dans le programme externe, on y accède avec process.argv.
Pour transmettre un volume de données plus important en paramètre,
il vaut mieux faire appel à la propriété stdin.
C’est un flux d’écriture dont le fonctionnement est identique
à process.stdin.
const {spawn} = require('child_process');
const subprocess = spawn('tr', ['0-9a-f', 'a-p']);
subprocess.stdout.on('data', (data) => {
console.log(String(data)); // (3)
});
subprocess.stdin.write('0123 abcd'); // (1)
subprocess.stdin.end(); // (2)-
Écrit
0123 abcddans le flux d’entrée. -
Signale au processus externe qu’il n’aura plus de donnée – le programme
trrendra la main dès qu’il nous aura tout transmis. -
Affiche
abcd klmn.
L’exécutable tr (fr.wikipedia.org/wiki/Tr_(Unix))
remplace des plages de caractères.
On lui a transmis des caractères en entrée et spécifié les plages de traduction
en arguments.
Nous avons utilisé la sortie standard pour lire les résultats.
L’exemple précédent revient au même que la commande suivante :
echo -n '0123 abcd' | tr 0-9a-f a-p abcd klmn
Dans ce cas précis, je trouve que l’instruction en ligne de commande est plus
concise que l’utilisation d’un script Node faisant appel à child_process.spawn().
J’aurais plutôt tendance à transmettre le résultat de cette commande
à l'entrée standard d’un script Node.
child_process.exec()
|
Exécute une commande et retourne son résultat. |
child_process.spawn()
|
Exécute une commande et retourne un objet processus. Le script Node et le nouveau processus peuvent communiquer entre eux. |
ChildProcess
process.on('message')
|
Se déclenche lorsque le processus enfant reçoit un message envoyé par l’autre script. |
process.kill()
|
Envoie un signal d’arrêt au processus enfant. |
process.send()
|
Envoie un message au processus enfant. |
process.stdin
process.stdout
process.stderr
|
Flux standards du processus enfant. Idéal pour envoyer et récupérer des données en continu. |
|
💬
|
Documentation Module child_process
La documentation du module |
6.10. process : en savoir plus sur le processus en cours
La module process retourne des informations
sur l’environnement dans lequel le script est exécuté.
À l’instar de console, la variable process
est globale.
const variables = Object.keys(process.env);
console.log(variables); // (1)
console.log(process.argv); // (2)-
Affiche quelque chose comme
['LANG', 'SHELL', 'PATH', 'HOME', 'USER', …]– voir plus bas, les “variables d’environnement”. -
Affiche
[ '…/v10.9.0/bin/node', '…/chapter-04/examples/process/intro.js' ]– voir plus bas, les “ arguments d’exécution”.
Notre code peut être interprété par Node
sur plusieurs types de machines
(ordinateur récent ou fatigué, Raspberry Pi, etc.) et sur différents
systèmes d’exploitation (Windows, Linux, macOS, etc.).
Nous avons avec le module process tout le loisir d’adapter nos scripts
à ces diverses conditions.
Les variables d’environnement sont définies au niveau du système d’exploitation. Elles contiennent des informations comme le répertoire courant, la langue du système d’exploitation, l’utilisateur système courant, le type de terminal, les emplacements d’installation des exécutables, etc.
On retrouve ces variables sous la forme d’un
objet ECMAScript nommé process.env :
node -p 'process.env'
{ ITERM_PROFILE: 'Default',
LANG: 'en_GB.UTF-8',
PWD: '/Users/oncletom/workspace/nodebook',
SHELL: '/bin/zsh',
TERM_PROGRAM_VERSION: '3.1.5',
TERM_PROGRAM: 'iTerm.app',
...
}
En créant des variables d’environnement, nous sommes en mesure de transmettre des informations contextuelles à nos programmes : des chemins d’accès à une base de données, si on est en situation de test ou de production, l’emplacement de fichiers nécessaires au fonctionnement de notre programme, etc.
Par exemple et par convention, la variable NODE_ENV est utilisée pour indiquer au programme
s’il est lancé dans le cadre du développement, de l’exécution des tests
ou s’il tourne sur le serveur de production.
- Variable d’environnement éphémère
-
La variable n’existe que pendant la durée de vie du programme. La définition
CLÉ=valeurest placée sur la même ligne que le programme en question.
NODE_ENV=production node process/env.js mode : production
- Variable d’environnement permanente
-
La variable existe pendant la durée de la session grâce à l’opérateur
exportsous Linux et macOS et avec l’opérateursetsous Windows.
La définitionexport CLÉ=valeurest placée sur sa propre ligne. Elle restera accessible par tout programme jusqu’à la fin de la session ou jusqu’à ce qu’on efface la variable.
export NODE_ENV=production node process/env.js mode : production
|
💡
|
Revenir en arrière Effacer une variable d’environnement
L’opérateur export NODE_ENV=dev echo $NODE_ENV unset NODE_ENV echo $NODE_ENV |
Voici le contenu du fichier process/env.js utilisé dans les exemples précédents :
const {NODE_ENV} = process.env;
if (NODE_ENV === 'dev') {
console.log('On est en mode développement.');
}
console.log('mode : %s', NODE_ENV);On notera que son comportement s’adapte à la présence et à la valeur
de la variable d’environnement NODE_ENV.
Elle est accessible dans Node en tant que process.env.NODE_ENV.
NODE_ENV=dev node process/env.js On est en mode développement. mode : dev
Nous verrons d’autres mises en situation des variables d’environnement pour configurer une application dans le chapitre 6 et pour déboguer une application en ligne de commande dans le chapitre 8.
Les arguments d’exécution sont des morceaux d’information transmis à un script Node. On les place à droite du nom du fichier :
node print-first.js salut "salut"
On utilise les arguments pour affiner le comportement d’un programme. Je pense par exemple au numéro du port sur lequel lancer un serveur web, une liste de fichiers à traiter ou encore des fonctionnalités à activer ou à désactiver.
Il faut imaginer les arguments comme des paramètres de fonction,
accessibles dans un programme Node dans
le tableau process.argv :
const [,,first_arg] = process.argv;
console.log(first_arg);Les deux premiers éléments de process.argv sont rarement utilisés.
Ils correspondent respectivement à l’emplacement de l’exécutable Node
et à l’emplacement du script.
Tous les autres arguments sont accessibles à partir de l’index 2 de
process.argv, dans l’ordre où ils sont placés :
node print-first.js salut ça va ? "salut"
Le script print-first.js affiche le premier argument.
On en conclut que les arguments sont séparés par le caractère “espace”.
Dans le cas où un argument doit contenir un espace, on l’encadre alors de guillemets :
node print-first.js "salut ça va ?" "oui et toi ?" "salut ça va ?"
L’inconvénient des arguments est que leur ordre compte et qu’il devient difficile de connaître leur rôle sans se référer au manuel d’utilisation.
C’est là qu’interviennent les options.
Comme leur nom l’indique, ce sont des arguments optionnels.
Elles sont préfixées de deux traits d’union (--).
On leur associe ou non une valeur.
node print-text.js "salut ça va ?" --uppercase SALUT ÇA VA ?
Quand on n’associe pas de valeur à une option,
on considère qu’elle équivaut à un booléen
de valeur true.
let [,,text] = process.argv;
if (process.argv.includes('--uppercase')) { // (1)
text = text.toLocaleUpperCase();
}
console.log(text);-
La condition est positive si l’on détecte
--uppercasedans la liste des arguments.
Les options se combinent très bien avec les arguments. Il faut les imaginer comme des interrupteurs.
Dans d’autres situations, on a besoin de passer une valeur à une option :
node print-text-limit.js "salut ça va ?" --limit 2 salut ça
L’exemple précédent illustre la césure d’une phrase après deux mots
lorsque l’option --limit est associée à la valeur `2`.
let [,,text] = process.argv;
const limitIndex = process.argv.indexOf('--limit'); // (1)
if (limitIndex >= 2) {
const limitValue = process.argv[limitIndex + 1]; // (2)
text = text.split(' ').slice(0, limitValue).join(' ');// (3)
}
console.log(text);-
On récupère l’index de l’option
--limitdans le tableauprocess.argv. -
On récupère la valeur de l’élément suivant
--limitdansprocess.argv. -
La troncature est paramétrée en fonction de la valeur associée à
--limit.
Au fond, les options sont des repères pour les utilisateurs de nos programmes. Elles leur permettent de s’interfacer avec leurs fonctionnalités, un peu à la manière des différents boutons qu’on retrouve en façade d’une machine à laver.
L’exemple suivant est totalement fictif, mais il illustre comment on s’interfacerait avec une machine à laver en ligne de commande :
machine-a-laver P-ECO 40 --fast --no-dry --room kitchen
Ce qu’il faut en comprendre, c’est qu’on démarrerait la machine située dans la cuisine avec un programme économique et à 40°C, en activant l’option rapide et en désactivant l’option séchage.
Nous verrons d’autres mises en situation pour passer des paramètres à une application en ligne de commande dans le chapitre 8.
Chaque processus système est doté de trois flux de données :
le flux d’entrée (stdin), le flux de sortie (stdout)
et le flux d’erreur (stderr).
Les flux standards peuvent être alimentés pendant la durée de vie du processus en utilisant peu de mémoire. On les utilisera pour passer le résultat d’un autre programme à notre script Node, pour informer l’utilisateur de notre programme, mais aussi pour consigner les erreurs.
Node expose ces flux standards via les variables process.stdin (entrée),
process.stdout (sortie) et process.stderr (erreur).
Chacune possède des méthodes pour écouter ce qui s’y passe,
pour y écrire du contenu et pour rediriger leur flux.
Commençons par l’utilisation de process.stdout pour écrire un message
dans notre terminal :
node process/stdout.js un deuxtrois quatre
Le code source de process/stdout.js fait appel à la fonction
process.stdout.write() par deux fois.
On notera que le caractère \n symbolise un retour à la ligne
(\r\n sous Windows) :
process.stdout.write('un deux');
process.stdout.write('trois\nquatre');Cela rappelle nos précédentes utilisations de la fonction console.log(),
qui se repose en effet sur process.stdout (voir encadré).
|
💡
|
Raccourci Les fonctions
console.log et console.error
La fonction d’affichage Elles ajoutent un retour à la ligne et des options de formatage pour notre confort. On en parle davantage dans la section sur le module |
Les flux de sortie et d’erreur sont manipulables en continu,
à l’aide d’utilitaires systèmes existants (grep, awk, etc.)
ou de programmes spécifiques (analyse de logs).
On peut ainsi se concentrer sur un programme qui fait juste ce dont on a besoin.
On laisse le travail de spécialisation à d’autres programmes.
Filtrons la sortie de l’exemple précédent sans écrire une ligne de code de plus.
Le programme grep (fr.wikipedia.org/wiki/Grep)
est fourni par défaut sur les systèmes Linux et macOS.
Il ne retourne que les lignes qui contiennent le motif
donné en argument :
node process/stdout.js | grep 'tre' quatre
La sortie standard de process/stdout.js est devenue l’entrée standard
de grep grâce à l’utilisation du pipe (|).
C’est le moment idéal pour regarder du côté de l’entrée standard de Node. Implémentons quelque chose qui transforme un message :
echo "un deuxtrois\nquatre" | node process/stdin-uppercase.js UN DEUXTROIS QUATRE
On aurait aussi pu réutiliser la sortie de l’exemple process/stdout.js :
node process/stdout.js | node process/stdin-uppercase.js UN DEUXTROIS QUATRE
Voyons comment cela fonctionne :
process.stdin.on('data', (chunk) => { // (1)
const text = chunk.toString(); // (2)
process.stdout.write(text.toLocaleUpperCase()); // (3)
});-
Cette fonction est appelée avec le morceau de données qui vient d’être lu par Node ; elle est appelée autant de fois que nécessaire, jusqu’à ce que toutes les données entrantes soient lues.
-
Le paramètre est de type Buffer – on souhaite le transformer en chaîne de caractères.
-
La chaîne de caractères est transformée en majuscules et écrite dans le flux de sortie.
Terminons avec la sortie erreur (process.stderr).
Elle fonctionne de manière identique à la sortie standard (process.stdout).
S’il n’y a visuellement aucune différence, la sortie erreur écrit son contenu
dans un canal différent – un descripteur différent.
On l’utilise pour déboguer des programmes, pour lister des erreurs ou des
contenus que l’on souhaite dissocier de la sortie standard.
L’exemple suivant affiche un nombre toutes les demi-secondes et l’état du compteur de nombres tous les cinq affichages :
node process/stdout-long.js 7 24 3 19 25 Compteur = 5 22 ...
|
💬
|
Rappel Interrompre un programme avec Ctrl+C
Un programme peut être interrompu à tout moment en utilisant la combinaison de touches Ctrl+C. |
const random = (limit) => Math.floor(Math.random() * limit);
let counter = 0;
setInterval(() => {
counter++;
process.stdout.write(`${random(30)}\n`); // (1)
if (Number.isInteger(counter / 5)) { // (2)
process.stderr.write(`Compteur = ${counter}\n`); // (3)
}
}, 500);-
Écrit un nombre entre 0 et 30 dans la sortie standard.
-
On vérifie si la valeur du compteur est divisible par 5 – c’est le cas si la division produit un entier au lieu d’un nombre à virgule.
-
Affiche
Compteur = 5puisCompteur = 10(et ainsi de suite) dans la sortie erreur.
On pourrait décider de n’afficher que le flux d’erreur.
Utilisons l’opérateur > pour rediriger la sortie standard vers un fichier :
node process/stdout-long.js > stdout.txt Compteur = 5 Compteur = 10 ...
En ouvrant le fichier stdout.txt, on voit
la liste de nombres générée par notre programme.
En maîtrisant les flux standards, on est capable de créer des programmes modulaires qui consomment du contenu sans avoir à connaître leur provenance. Les données circulent depuis et vers des programmes externes, des fichiers ou des sites web distants.
Pour mieux comprendre la logique de flux continu que l’on vient de découvrir,
je vous invite à lire la section liée au module stream.
On y détaillera la liste des événements à écouter, ainsi que les différentes
méthodes d’écriture, de pause et de lecture.
Un processus système reçoit et émet des données, mais il peut aussi
écouter des événements grâce à la fonction process.on.
console.log('Le processus démarre');
process.on('exit', (code) => {
console.log(`Le processus termine avec le code ${code}`);
});Cet exemple illustre l’événement exit, qui est déclenché quand le processus se termine.
À ce titre, un code de sortie est fourni pour signaler l’état dans
lequel le programme se termine.
On parlera davantage du code de sortie et de sa signification
dans la section “Mettre fin au processus”.
Lançons le script précédent :
node process/exit.js Le processus démarre Le processus termine avec le code 0
Tout s’est passé correctement.
Le code de sortie est alors 0.
Si le programme venait à se terminer de manière imprévue, le code serait différent. L’exemple suivant provoque volontairement une erreur en faisant référence à une variable qui n’existe pas :
process.on('exit', (code) => {
console.log(`Le processus termine avec le code ${code}`);
});
console.log(jenexistepas);Lançons le script :
node process/exit-error.js
Le processus termine avec le code 1
ReferenceError: jenexistepas is not defined
at Object. (/.../examples/process/exit-error.js:5:13)
Cette fois-ci, le code de sortie est 1.
Cela correspond à une erreur qui n’a pas été capturée.
Le reste du message décrit pourquoi l’erreur s’est manifestée.
D’autres événements liés au cycle de vie de nos applications sont disponibles :
| Événement | Paramètres | Raison du déclenchement |
|---|---|---|
|
|
Le programme se termine et va rendre la main au système d’exploitation. |
|
|
Une promesse a échoué
et n’a pas été capturée à l’aide de la méthode |
|
|
Une erreur s’est produite et n’a pas été capturée.
Si rien n’est fait, le processus va s’arrêter avec un code erreur. |
|
|
Un processus parent nous envoie un message. |
La méthode process.on est à l’écoute des signaux système.
Par exemple, la combinaison de touches Ctrl+C met en réalité
un signal d’interruption qui répond à l’identifiant SIGINT.
Node gère ces signaux pour nous, mais on peut aussi se mettre à les écouter et décider de faire autrement que son comportement par défaut.
Par exemple, affichons l’heure de l’arrêt du processus avant de rendre la main :
const log = (msg) => {
console.log(`${new Date().toISOString()} - ${msg}`);
}
log('Processus démarré'); // (1)
process.on('SIGINT', () => { // (2)
log('Processus terminé (manuellement)');
process.exit(0); // (3)
});
setTimeout(() => { // (4)
log('Processus terminé (timeout)');
process.exit(0);
}, 5000)-
Un premier message s’affiche au démarrage du script.
-
Cette fonction se déclenche lors de la réception du signal d’interruption (
SIGINT), lorsque le système d’exploitation lui relaie notre combinaison de touches Ctrl+C. -
La fonction
process.exit()termine le processus. -
Sinon, ce chronomètre mettra fin au processus au bout de 5 secondes.
En pratique le résultat ressemble à ceci :
node process/interrupt.js
2018-03-16T10:58:32.855Z - Processus démarré
Ctrl+C
2018-03-16T10:58:40.000Z - Processus terminé (manuellement)
En plus du signal SIGINT, Node nous relaie les signaux suivants :
| Événement | Raison du déclenchement |
|---|---|
|
Interruption de la commande en cours |
|
Demande au processus de s’arrêter |
|
Node reçoit le signal d’attacher l'inspecteur |
|
Le terminal est en train d’être fermé |
|
Le terminal a été redimensionné |
SIGKILL est un autre événement important, mais on ne peut pas l’écouter.
Quand il est émis, le processus doit être arrêté quoiqu’il arrive.
On l’utilise justement en dernier recours, quand SIGINT
et SIGTERM ne font pas effet ; par exemple à cause d’un bogue dans notre code,
ou d’une ressource qui ne rend pas la main.
Un processus Node se termine quand il n’a plus d’instructions à exécuter.
Ce peut être provoqué via
l'émission d’un signal extérieur, mais aussi de l’intérieur
par l’intermédiaire de la fonction process.exit().
On utilise cette fonction car le programme a atteint son but. On le fait aussi lorsqu’on intercepte une erreur en souhaitant effectuer un traitement spécial avant de mettre fin au processus. Il se peut aussi qu’il vaille mieux terminer l’application en cas de perte d’accès à des ressources distantes (base de données, stockage de fichiers) au lieu de présenter une application web instable.
L’exemple suivant illustre que l’on souhaite clôturer notre script si on trouve le bon nombre :
node process/exit-devinette.js JEU ! Trouve le nombre auquel je pense : 10ENTRÉE Hm hm, essaie encore. 3ENTRÉE Tu as trouvé, bravo !
Dans cet exemple, on écoute l’utilisateur de manière indéfinie, jusqu’à ce qu’il
ou elle trouve le bon nombre.
Lorsque c’est le cas, on interrompt le programme en transmettant
un code de sortie de réussite : le code 0.
const secret_number = Number(process.argv[2] || 3); // (1)
console.log('JEU ! Trouve le nombre auquel je pense :');
process.stdin.on('data', (chunk) => { // (2)
if (parseFloat(chunk) === secret_number) {
console.log('Tu as trouvé, bravo !');
process.exit(0); // (3)
}
else {
console.log('Hm hm, essaie encore.'); // (4)
}
});-
Le nombre secret est
3par défaut, sauf s’il est passé en argument du script. -
Cette fonction est invoquée à chaque saisie suivie de l’appui sur la touche ENTRÉE.
-
Cette ligne met fin au script, après avoir affiché un message de félicitations.
-
Ce message s’affiche à chaque saisie erronée, jusqu’à ce que le nombre secret soit trouvé.
On pourrait tout à fait imaginer une variante de ce script dans laquelle
on limiterait le nombre de mauvaises réponses.
Lorsqu’on atteindrait cette limite, le programme utiliserait un code de sortie
différent de 0.
Le code 9 ferait l’affaire puisqu’il indique qu’un argument invalide a été
passé.
|
💬
|
Avancé process.abort()
Comme avec La fonction génère un fichier de débogage (core file) qui contient tout le contenu
de la mémoire utilisée par Node.
Ce fichier s’analyse avec des logiciels avancés comme |
|
💬
|
Documentation Module process
La documentation du module |
6.11. stream : manipuler des flux de données
Le module stream contient les éléments de base pour lire, écrire et
transformer des flux de données rapidement et avec peu de mémoire.
Créer ses propres flux est une chose assez compliquée à réaliser. Dans cette section, nous allons nous focaliser sur l’utilisation des modules Node qui génèrent de tels flux.
const {createReadStream} = require('fs');
createReadStream(__filename) // (1)
.on('data', (data) => { // (2)
console.log('%d octets lus', data.length); // (3)
});-
On crée un flux de lecture qui ouvre le fichier courant (
__filename). -
Invoque cette fonction à chaque morceau de données lu.
-
Affiche le nombre d’octets lus dans ce morceau.
node stream/intro.js 214 octets lus
Un flux de lecture consomme les données petit à petit.
Il correspond à une instance de l’objet stream.Readable.
L’exemple précédent n’a affiché qu’un seul morceau car la taille maximale
par défaut est d’environ 16 Ko.
const {createReadStream} = require('fs');
createReadStream(__filename, {highWaterMark: 100}) // (1)
.on('end', () => console.log('Lecture terminée')) // (2)
.on('data', (data) => {
console.log('%d octets reçus', data.length);
});-
On spécifie cette fois qu’on lit
100 octetsà la fois. -
Affiche
Lecture terminéelorsque tous les morceaux ont été lus.
L’option highWaterMark adapte le débit de lecture.
Cette valeur est exprimée en octets.
Plus ce nombre est petit, moins Node utilise de mémoire :
node stream/read.js 100 octets lus 100 octets lus 78 octets lus Lecture terminée
Le mécanisme de flux s’applique également à l’écriture.
Un flux d’écriture écrit des données petit à petit.
Il correspond à une instance de l’objet stream.Writeable.
L’exemple suivant illustre une succession d’écritures dans un même flux :
const {createWriteStream, readFile} = require('fs');
const {join} = require('path');
const dest = join(__dirname, 'debug.txt');
const stream = createWriteStream(dest); // (1)
stream.on('finish', () => {
readFile(dest, (error, data) => { // (4)
console.log(String(data));
});
});
stream.write('Hell'); // (2)
stream.write('o Worl');
stream.end('d!'); // (3)-
On crée un flux d’écriture vers le fichier
stream/debug.txt. -
Écrit
Helldans le flux. -
Écrit
d!dans le flux et signale que nous n’avons plus de données à transmettre. -
L’utilisation de
stream.end()déclenche l’événementfinish– nous lisons le contenu du fichier à ce moment là.
Cette écriture par morceaux a pour effet de réduire la pression mémoire exercée par Node sur le système d’exploitation et pour le reste du programme. Ce mécanisme est particulièrement adapté lorsque l’écriture prend du temps ou implique un certain volume de données.
Les flux de lecture et d’écriture se combinent.
Les données lues depuis une source (Readable) sont redirigées vers
une destination (Writeable) à l’aide de la fonction pipe() :
const {createReadStream, createWriteStream} = require('fs');
const {join} = require('path');
const filename_copy = join(__dirname, 'copie.js');
const source = createReadStream(__filename); // (1)
const dest = createWriteStream(filename_copy); // (2)
source.pipe(dest) // (3)
.on('finish', () => console.log('Copie terminée !')); // (4)-
On crée un flux de lecture.
-
On crée un flux d’écriture.
-
On redirige le flux de lecture vers celui d’écriture.
-
La redirection retourne le flux d’écriture, que l’on écoute pour savoir quand il a terminé d’écrire sur le disque.
Dans cet exemple, nous avons pris deux fichiers respectivement comme source de lecture
et destination d’écriture.
Nous avons assemblé les deux flux avec pipe() puis détecté la fin de la copie.
|
💬
|
Unix Opérateur pipe (
|)La fonction Les morceaux de données d’un premier programme sont transmis en entrée à un second programme. Ici, le mécanisme s’applique à des fonctions Node. |
L’utilisation de pipe() semble superflue pour copier des fichiers.
À vrai dire, la fonction fs.copyFile() fait exactement la même chose.
Toutefois, le mécanisme de redirection proposé par pipe() est modulaire et composable.
On peut par exemple diriger une source de données vers plusieurs flux d’écriture
en même temps.
const fs = require('fs');
const {join} = require('path');
const filename_copy = join(__dirname, 'copie.js');
const read = fs.createReadStream(__filename);
read.on('end', () => console.log('Lecture terminée !'));
read.pipe(fs.createWriteStream(filename_copy)); // (1)
read.pipe(process.stdout); // (2)-
Écrit une copie du fichier comme dans l’exemple
stream/pipe.js. -
Redirige le contenu de lecture vers la sortie standard de notre terminal.
Cette technique agit comme une gare de triage : nous avons la liberté d’agir sur les données avant de les envoyer vers leur flux d’écriture distinct.
On peut aussi transformer les contenus à la volée en utilisant plusieurs
fois la fonction pipe().
Les données sont passées à des objets capables de lire et d’écrire des flux.
C’est le cas du module zlib, responsable de compresser et de
décompresser des données :
const {createReadStream} = require('fs');
const {createGzip} = require('zlib');
createReadStream(__filename)
.pipe(createGzip()) // (1)
.pipe(process.stdout); // (2)-
Compresse les données à la volée.
-
Les données compressées sont transmises à la sortie standard.
Cet exemple devrait afficher le contenu de notre fichier source avec une taille réduite :
node stream/pipe-transform.js
L’affichage semble bizarre et c’est normal : ce sont des données compressées au format Gzip – un format de compression libre.
Le programme Unix gzip sait décoder des données compressées dans ce format.
Il sait aussi les décoder à la volée avec un pipe :
node stream/pipe-transform.js | gzip
Nous avons vu comment transmettre des flux de données de manière interopérable entre un script Node et un programme externe, entre deux programmes externes et entre deux scripts Node.
stream.pipe()
|
Redirige un flux de lecture vers un flux d’écriture. |
stream.on('data')
|
Se déclenche lorsqu’un morceau de données a été lu. |
stream.on('error')
|
Se déclenche lorqu’une erreur se produit. |
stream.on('end')
|
Se déclenche lorsqu’il n’y a plus de données à lire. |
stream.on('readable')
|
Se déclenche lorsque la lecture de données est prête à démarrer. |
stream.write()
|
Écrit des données dans le flux. |
stream.end()
|
Signale que nous n’avons plus de données à transmettre. |
stream.on('drain')
|
Se déclenche lorsque la mémoire d’écriture est vide et prête à accepter de nouvelles données. |
stream.on('error')
|
Se déclenche lorsqu’une erreur se produit. |
stream.on('finish')
|
Se déclenche à la clôture du flux d’écriture. |
|
💬
|
Documentation Module stream
La documentation du module |
6.12. D’autres modules pour aller plus loin
Node embarque d’autres modules que ceux listés précédemment. Ils nécessitent des connaissances sur des sujets bas niveau, plus proches du matériel et des protocoles réseau.
cluster-
Gère la distribution d’une application sur plusieurs CPU d’un même ordinateur.
crypto-
Fonctions cryptographiques pour chiffrer, signer et vérifier des données.
dgram-
Création et consommation de ressources UDP.
dns-
Résolution et lecture d’enregistrements DNS.
net-
Création et consommation de ressources TCP. Les modules
http,httpsethttp2se basent dessus. readline-
Manipulation ligne par ligne d’un flux. Ce module est particulièrement utilisé dans des applications en ligne de commande (chapitre 8), pour mettre à jour une barre de progression et animer des éléments d’affichage.
tty-
Gestion d’interface de terminal en mode texte. Le module
readlinese base dessus. v8-
Lecture et écriture d’instructions de la machine virtuelle V8 dans le processus actuel.
vm-
Création de nouveaux contextes d’interprétation de la machine virtuelle V8.
zlib-
Compression et décompression de données (Gzip, Inflate/Deflate). Ces formats sont utilisés pour la compression de requêtes HTTP.
7. Créer ses propres modules Node
Les modules de base nous fournissent de nombreuses fonctionnalités.
Nous pouvons réutiliser le même mécanisme pour
organiser notre code dans plusieurs fichiers.
C’est un mécanisme comparable à ce que l’on retrouve en Python (import),
PHP (require) et Ruby (require et require_relative).
7.1. Importer et exporter des valeurs
const number = 42;Le fichier d’exemple modules/enfant.js contient une variable, number.
Essayons de la réutiliser dans le fichier modules/parent.js
à l’aide de la fonction require().
const enfant = require('./enfant.js'); // (1)
console.log(enfant.number); // (2)
console.log(enfant); // (3)-
Contrairement aux modules de base, on passe un chemin relatif au fichier courant.
-
Est-ce que cela affichera la valeur de la variable
number? -
Mais au fond, que contient notre variable
enfant?
Exécutons le fichier modules/parent.js avec Node pour en avoir le cœur net :
node modules/parent.js
undefined
{}
Nous pouvons en tirer un apprentissage important : on ne peut pas voir ce qu’il y a dans un module depuis l’extérieur.
Choisissons maintenant ce que l’on souhaite exporter en affectant
la valeur de notre choix à module.exports :
const number = 42;
module.exports = number;Comment cela ça se traduit-il lorsqu’on l’appelle avec require() ?
const enfant = require('./enfant-export.js');
console.log(enfant.number); // (1)
console.log(enfant); // (2)-
Affiche
undefined. -
Affiche
42.
module.exports rend visible depuis l’extérieur ce qui est exporté par un module.
Par défaut, module.exports est un objet.
Essayons maintenant d’exporter plusieurs valeurs en une seule fois.
const number = 42;
module.exports.number = number;
module.exports.random = (limit = 100) => {
return Math.floor(Math.random() * limit)
};Nous avons créé deux nouvelles valeurs : number (un nombre) et
random() (une fonction).
const enfant = require('./enfant-export-multiple.js');
console.log(enfant.number); // (1)
console.log(enfant.random()); // (2)
module.exports = enfant.random; // (3)-
Affiche
42. -
Affiche un nombre aléatoire entre 0 et 100.
-
Réexporte la fonction
enfant.number.
|
💡
|
Raccourci Exporter un objet
L’utilisation de la syntaxe d’objet raccourcie évite la répétition du nom des variables lors de l’export.
|
En résumé, pour Node, tout fichier .js est un module.
Le mécanisme d’import et d’export est basé sur des chemins de fichiers.
Si on n’utilise pas de chemin, Node pense que l’on fait
référence à un module de base ou à un
module npm
(chapitre 5).
|
💬
|
Histoire Modules CommonJS
Le mécanisme de modules implémenté dans Node est basé sur la spécification CommonJS, à peu de choses près. |
7.2. Aller plus loin avec require()
Lorsqu’on fait appel à la fonction require(), Node effectue les actions suivantes :
-
Résout le chemin vers le module en question.
-
Lit du fichier.
-
Interprète le code.
-
Exécute le code.
-
Retourne la valeur de
module.exports.
L’utilisation de require() est synchrone et bloquante.
Si l’exécution du code dans le module chargé prend du temps
– code lent, accès à une ressource distante – le temps de chargement
du module sera affecté.
require() permet de charger trois types de modules :
- Fichiers relatifs au module actuel
-
require('./module.js')cherche le fichiermodule.jsdans le répertoire courant.require('../module.js')cherchemodule.jsdans le répertoire parent. - Modules Node de base
-
Ils sont disponibles avec chaque installation de Node.
- Modules
npm -
Ils sont disponibles avec une étape d’installation supplémentaire (chapitre 5).
Node met les modules en cache. Si on inclut deux fois le même module, le deuxième import ira directement à la dernière étape de la liste d’actions. Cela implique aussi que si le module modifie une de ses variables privée, cette modification affectera le deuxième import.
Voici un module illustrant une variable privée et une variable exportée :
let counter = 0; // (1)
const increment = () => ++counter;
module.exports = increment; // (2)-
Variable privée.
-
incrementest rendue publique à cet endroit – la fonction incrémente la variable privéecounter.
Nous allons importer ce module par deux fois, dans deux variables différentes.
const first = require('./increment.js');
const second = require('./increment.js');
console.log(first()); // (1)
console.log(first()); // (2)
console.log(second()); // (3)-
Affiche
1. -
Affiche
2. -
Affiche
1ou3?
Quel est le verdict à votre avis ? Rien ne vaut une vérification, quitte à remettre en question notre avis initial :
node modules/double-import.js 1 2 3
Il faut garder cette information en tête lorsqu’on importe un module. Ce mécanisme se transforme en atout afin de partager une variable entre plusieurs modules. Il est pratique dans le cas d’un cache de données ou d’une configuration partagée.
Enfin, plusieurs problèmes sont susceptibles d’apparaître lors du chargement d’un module :
-
Le chemin vers le module est erroné ;
-
Le module contient une erreur de syntaxe.
Node lance alors une exception et le programme s’arrête aussitôt.
|
💬
|
Documentation Module “modules”
L’intégralité des variables, fonctions et classes du module |
7.3. Le futur : les modules ECMAScript
Pendant que le mécanisme de modules de Node montait en puissance, les navigateurs web étaient en attente d’une solution native. La spécification des modules ECMAScript a été validée en 2013, mais les navigateurs ont tardé à en implémenter le mécanisme : en 2017 pour la plupart. C’est le cas du navigateur web Chrome et de sa machine virtuelle V8.
|
🚨
|
Attention Fonctionnalité expérimentale
Si la syntaxe des modules ECMAScript est standardisée, ce n’est pas encore aussi stable du côté de Node. Les modules ECMAScript sont suffixés de l’extension |
Reprenons l’exemple modules/increment.js pour le
transformer en module ECMAScript.
let counter = 0;
export default () => ++counter; // (1)
export const reset = () => counter = 0; // (2)-
Export par défaut.
-
Export nommé.
La syntaxe export sert à exporter des variables.
Elle se combine avec import :
import increment from './increment.js'; // (1)
console.log(increment());-
On n’importe ici que la valeur par défaut.
Il ne nous reste maintenant plus qu’à exécuter notre script .mjs
pour observer le résultat.
On notera l’utilisation de --experimental-modules :
node --experimental-modules modules/ecmascript.mjs (node:35074) ExperimentalWarning: The ESM module loader is experimental. 1
Reprenons cet exemple pour importer plusieurs exports d’un coup :
import increment, {reset} from './increment.mjs'; // (1)
increment();
console.log(increment());
reset(); // (2)
console.log(increment());-
On importe la valeur par défaut, ainsi qu’une valeur nommée – c’est particulièrement pratique pour sélectionner avec finesse ce que l’on veut utiliser d’un module.
-
La fonction
reset()remet le compteur à zéro.
On notera au passage qu’on utilise la décomposition d’objet pour extraire un export nommé depuis un module ECMAScript.
node --experimental-modules modules/ecmascript-multiple.mjs (node:35074) ExperimentalWarning: The ESM module loader is experimental. 2 1
La fonction reset() a bien remis le compteur à zéro entre-temps.
Objectif accompli !
Résumons les différences notables avec le mécanisme de modules Node :
-
Tous les appels à
importdoivent se faire en début de fichier. -
On ne peut pas utiliser
importde manière dynamique (dans unif … elsepar exemple). -
On peut exporter une variable par défaut et plusieurs variables nommées.
-
Il est possible d’importer des modules Node depuis un module ECMAScript – l’inverse n’est pas vrai.
-
Les fichiers doivent être suffixés par
.mjs.
Ce dernier point est le plus embêtant car il ralentit l’interopérabilité entre les scripts destinés au développement web front-end et les scripts Node.
L’histoire nous dira si les modalités s’assoupliront avec le temps.
|
💡
|
npm Module esm
Le module node -r esm modules/ecmascript.js 1 node -r esm modules/ecmascript.mjs 1 Pour en savoir plus sur l’option |
|
💬
|
Documentation Modules ECMAScript
L’intégralité des fonctionnalités des modules ECMAScript est documentée sur le site web du projet Node. La documentation contient des informations à jour et qui ne sont pas forcément listées dans cet ouvrage. |
8. S’en sortir quand ça ne se passe pas comme prévu
On fait toutes et tous des erreurs. Notre code va forcément mener à des plantages applicatifs. La nature des causes varie et affecte notre lecture des messages d’erreur.
Cette section a pour intention de nous aider à prendre confiance dans ce qu’on voit et de piocher l’information qui va nous aider à résoudre le problème.
8.1. Une erreur est nichée dans notre code
Il y a deux familles d’erreurs dans du code ECMAScript : celles de syntaxe et celles d’exécution.
Dans tous les cas, Node lance une exception complétée d’une trace d’erreur. Le but est de comprendre où l’interpréteur se prend les pieds dans le tapis et quel est le chemin parcouru au sein du code pour y parvenir.
Commençons avec une erreur de syntaxe :
node syntax-error.js
console.log('oups j'ai fait une erreur de guillemets);
^^^^^^^^
SyntaxError: missing ) after argument list
at new Script (vm.js:74:7)
at createScript (vm.js:246:10)
at Object.runInThisContext (vm.js:298:10)
Une erreur de syntaxe est immédiate. Node la détecte lorsqu’il parse notre code.
Dans l’exemple précédent, Node indique qu’il manque une parenthèse après le deuxième guillemet, car c’est le symbole que l’interpréteur attend. En effet, le guillemet indique une intention incorrecte : on ne veut pas qu’il signifie la fin de la chaîne, mais qu’il représente un caractère apostrophe dans la chaîne.
La correction à entreprendre ne sera pas d’ajouter une parenthèse après le
guillemet mais bien de l’échapper en le préfixant d’un caractère \.
Node l’interprétera alors correctement.
Penchons-nous à présent sur les erreurs provoquées lorsque le code est exécuté :
node process/exit-error.js
console.log(jenexistepas);
^
ReferenceError: jenexistepas is not defined
at Object. (/.../chapter-04/examples/process/exit-error.js:5:13)
at Module._compile (module.js:643:30)
Le marqueur +^+ indique l’emplacement où le problème est rencontré.
La ligne en-dessous documente le type d’erreur (ReferenceError)
en précisant ce qui n’est pas défini (la variable jenexistepas).
La notation exit-error.js:5:13 indique que l’origine de l’erreur
se trouve à la ligne 5 du fichier exit-error.js.
Pour y remédier, il faut vérifier si on appelle bien la bonne variable ou la créer avec la valeur attendue le cas échéant.
Les erreurs d’exécution sont pernicieuses ; elles sont parfois provoquées après le démarrage de l’application. Dans l’exemple qui suit, l’une d’elles se produit deux secondes après le démarrage du script :
node runtime-error.js
setTimeout(() => console.log(secret.toLocaleUperCase()), 2000);
^
TypeError: secret.toLocaleUperCase is not a function
at Timeout.setTimeout [as _onTimeout] (/.../chapter-04/examples/runtime-error.js:4:37)
La notation runtime-error.js:4:37 indique que l’origine de l’erreur
se trouve à la ligne 4 du fichier runtime-error.js, colonne 37.
Le type d’erreur (TypeError) signifie qu’on cherche à manipuler une variable
de manière inattendue par rapport à son type.
Le message d’erreur nous précise qu’on appelle comme une fonction quelque chose
qui ne serait donc pas une fonction.
En effet, le nom de la fonction est mal orthographié et secret.toLocaleUperCase
vaut undefined.
L’erreur sera corrigée en utilisant secret.toLocaleUpperCase.
|
💡
|
npm Module eslint
Le module On apprendra à le configurer dans l'annexe A. |
Les erreurs affichées affichent des informations importantes. Si elles n’indiquent pas forcément le chemin de résolution évident, elles demandent qu’on cherche à en comprendre la nature.
|
💡
|
npm Module pretty-error
Le module node -r pretty-error/start process/exit-error.js |
8.2. Une erreur est retournée dans une fonction de rappel
La fonction de rappel est un des moyens de retourner le résultat d’une exécution asynchrone. Par convention, le premier paramètre est une erreur.
Ce paramètre est nul (null) ou indéfini (undefined) lorsqu’il n’y a pas eu
d’erreurs en cours de route.
En revanche, il contient un objet d’erreur lorsque un problème s’est produit.
'use strict';
const {readFile} = require('fs');
readFile('je-n-existe-pas.txt', (error, content) => {
if (error) { // (1)
console.error(error.message); // (2)
console.error(error); // (3)
return;
}
console.log(String(content));
});-
On vérifie la présence de l’erreur.
-
error.messagecontient une raison textuelle de l’erreur. -
Affichage de l’objet d’erreur complet.
node errors/callback.js
ENOENT: no such file or directory, open 'je-n-existe-pas.txt'
{ Error: ENOENT: no such file or directory, open 'je-n-existe-pas.txt'
errno: -2,
code: 'ENOENT',
syscall: 'open',
path: 'je-n-existe-pas.txt' }
L’erreur affichée nous précise que le fichier demandé n’existe pas.
Son code (ENOENT) signifie la même chose, mais a l’avantage d’être plus
facile à vérifier dans une condition.
L’objet error donné en argument de la fonction de rappel est utile
pour vérifier des détails précis de l’erreur et mieux interagir avec
au niveau du code.
Nous y retrouvons le type d’erreur (errno),
la référence vers la ressource concernée (path) et le nom de la fonction
système utilisée par Node pour accéder à la ressource (syscall).
La valeur et la signification du code d’erreur varie en fonction
du module Node employé à ce moment-là.
Le module fs ne retourne pas les mêmes codes
que le module http.
Les appels à des ressources système retournent
une variété de codes d’erreur.
La décision nous appartient de savoir quoi faire quand l’erreur se produit.
Doit-on arrêter le programme avec process.exit() ?
Passe-t-on à la suite en considérant que ce n’est pas grave ?
Ou peut-être que ce fichier était censé exister et qu’on devrait
informer l’équipe de maintenance et
afficher une page d’erreur côté utilisateur.
8.3. Une erreur est retournée dans une promesse
La gestion d’erreur des promesses
s’effectue à l’aide de la fonction .catch().
'use strict';
Promise.resolve('ok')
.then((message) => {
throw new Error('Oops !'); // (1)
})
.catch((error) => console.error(error)); // (2)-
On génère une erreur dans notre code.
-
L’objet d’erreur est transmis à la prochaine occurrence de
.catch().
Le contenu de l’erreur est accessible dans le seul argument de la fonction
de rappel passée à .catch().
node errors/promise.js
Error: Oops !
at Promise.resolve.then (/.../chapter-04/examples/errors/promise.js:5:11)
at process._tickCallback (internal/process/next_tick.js:178:7)
La trace indique que l’erreur s’est produite à la ligne 5,
dans la méthode .then() suite à l’utilisation de Promise.resolve().
L’utilisation multiple de .catch() nous aide à gérer finement les erreurs :
'use strict';
Promise.reject(new Error('Oops !'))
.catch((error) => {
console.error('Erreur : %s', error.message); // (1)
return 'Aaah'; // (2)
})
.then((message) => console.log(message)) // (3)
.catch((error) => console.error(error)); // (4)-
On gère l’erreur en la signalant dans le terminal.
-
La fonction de rappel a la possibilité de retourner un résultat.
-
Ce résultat est transmis à la prochaine occurrence de
.then(). -
Dans ce cas, le dernier
.catch()n’affiche rien car nous n’avons pas rencontré d’autre erreur entre-temps.
'use strict';
Promise.resolve('ok')
.then(() => {
throw new Error('Oops !');
});L’absence de .catch() provoque un plantage applicatif et le délenchement
de l'événement de processus unhandledRejection :
node errors/promise-no-catch.js
(node:27412) UnhandledPromiseRejectionWarning: Error: Oops !
at Promise.resolve.then (/.../chapter-04/examples/errors/promise-no-catch.js:5:11)
at process._tickCallback (internal/process/next_tick.js:178:7)
L’affichage de UnhandledPromiseRejectionWarning indique que l’erreur s’est
produite mais qu’aucun .catch() ne l’a pris en charge.
Nous savons cependant que l’erreur s’est produite dans la méthode .then()
suite à l’utilisation de Promise.resolve().
8.4. Une erreur est retournée dans un événement
Tout élément doté d’une méthode .on() a un événement spécial : .on('error').
Il est appelé à chaque fois qu’une erreur se produit.
'use strict';
process.emit('error', new Error('Oops !')); // (1)
process.on('error', (error) => console.error(error)); // (2)-
On émet un événement
erroravec un objetErrorprécisant la nature du problème. -
L’objet d’erreur est transmis à l’événement
error.
node errors/on-error.js
Error: Oops !
at Object.<anonymous> (/.../chapter-04/examples/errors/on-error.js:5:23)
at Module._compile (internal/modules/cjs/loader.js:678:30)
La trace d’erreur est similaire à celle des promesses et des fonctions de rappel. Le message d’erreur précise le problème tandis que son origine (fichier, ligne) nous indiquent quoi regarder pour mieux comprendre la cause.
Si une erreur est émise et si aucune fonction n’est à l’écoute,
l’événement uncaughtException est produit :
'use strict';
process.emit('error', new Error('Oops !'));node errors/on-error-uncaught.js
events.js:167
throw er; // Unhandled 'error' event
^
Error: Oops !
at Object.<anonymous> (/.../chapter-04/examples/errors/on-error-uncaught.js:3:23)
at Module._compile (internal/modules/cjs/loader.js:678:30)
La section liée au module events explique plus en détail
la gestion des événements.
On les retrouve par exemple dans les modules http, stream
et process.
8.5. Une erreur est renvoyée par le système d’exploitation
L’accès à une ressource distante est plus complexe qu’il n’y paraît car les erreurs sont de natures variées et sujettes à interprétation au cas par cas, en fonction de notre intention et du contexte d’exécution.
Les erreurs système indiquent la raison du problème.
| Code erreur | Raison | Piste de résolution |
|---|---|---|
|
Permission refusée : nous n’avons pas le droit d’accéder à cette ressource. |
Changer les permissions d’accès sans mettre en péril la sécurité. |
|
Adresse déjà utilisée : nous tentons de créer une ressource réseau alors qu’une interface existe déjà à la même adresse. |
Vérifier l’origine du serveur déjà en place à cette adresse. Attribuer une autre adresse/port à la ressource réseau. |
|
La ressource distante a refusé la connexion. |
Vérifier si c’est normal que la ressource distante soit inactive. Vérifier qu’on se connecte à la bonne ressource. |
|
La ressource distante a été interrompue en cours de route. |
Retenter la connexion. Vérifier la stabilité de la connexion réseau. |
|
La ressource à créer existe déjà. |
C’est un problème seulement si la ressource n’était pas censée exister au préalable. |
|
Trop de fichiers sont ouverts simultanément. |
Les systèmes d’exploitation peuvent travailler sur une quantité finie de fichiers. Peut-être que vous avez ouvert trop de fichiers en même temps. Fermer l’accès aux fichiers ouverts. |
|
Ressource inexistante. |
Vérifier que le chemin d’accès est correct. Inspecter la raison de l’inexistance de la ressource. |
|
L’opération n’est pas autorisée. |
Des droits d’administration sont nécessaires pour effectuer cette opération. |
|
L’accès à la ressource distante a été interrompu. |
Retenter l’opération. |
|
L’opération a été annulée car la ressource distante a mis trop de temps pour aboutir. |
Retenter l’opération. Vérifier la disponibilité de la ressource distante. S’assurer que le volume demandé n’est pas trop important. |
8.6. Le programme ne se termine pas
Il arrive qu’un programme ne se termine pas contrairement à nos attentes. Il peut y avoir plusieurs raisons à cela :
-
Une ressource distante met du temps à répondre – un timeout déclenchera une erreur (généralement sous 30 s).
-
Un traitement prend du temps.
-
Un événement est en cours d’écoute – typiquement un serveur web qui attend des requêtes entrantes.
-
Une erreur n’a pas été capturée et perturbe les instructions suivantes.
Il faudra inspecter le système pour en savoir plus et observer la consommation mémoire et CPU du processus Node en question.
Peut-être qu’il faudra sonder le programme pour déceler le point de blocage. L'inspecteur Node est un outil particulièrement adapté à cet usage.
|
💡
|
npm Module debug
Le module On apprendra à le configurer dans l'annexe A. |
8.7. Une alerte de dépréciation s’affiche
Un des objectifs de l’équipe développant Node est de maintenir la stabilité de la plate-forme. Certains de leurs choix de conception sont revisités en changeant leur comportement ou en les retirant des modules de base.
Quand ce changement affecte notre code, une alerte de dépréciation s’affiche. Par exemple :
const a = new Buffer(10);node deprecation-warning.js (node:8130) [DEP0005] DeprecationWarning: Buffer() is deprecated due to security and usability issues. Please use the Buffer.alloc(), Buffer.allocUnsafe(), or Buffer.from() methods instead.
Nous avons ainsi le temps de modifier notre code pour migrer vers la nouvelle recommandation petit à petit.
9. Les différences d’ECMAScript entre Node et les navigateurs web
Puisqu’on utilise du code ECMAScript avec Node et avec les navigateurs web, qu’est-ce qui les distingue vraiment ?
9.1. L’absence du DOM et des variables window et document
Dans Node, il n’est pas possible de faire appel aux variables window
et document (raccourci pour window.document).
Ces variables représentent respectivement la fenêtre/onglet et le document
HTML interprété par le navigateur web.
Les fonctions document.querySelector() et document.createElement()
relèvent du DOM (Document Object Model), une représentation JavaScript interactive
du document HTML.
L’équivalent de window pour Node serait la variable process :
elle décrit le processus exécutant notre code.
|
💬
|
Documentation Variables globales
La documentation des variables globales est disponible sur le site officiel de Node : |
9.2. Il n’y a pas d’interface graphique
Suite logique du point précédent : Node n’a pas d’interface graphique. Le code exécuté n’affiche rien en tant que tel, à part les messages dirigés vers la console.
L'inspecteur Node est un moyen de visualiser l’état interne d’un script.
On peut toutefois construire des applications graphiques en ligne de commande (chapitre 8).
9.3. Le mécanisme de modules
Pour l’instant, Node utilise un mécanisme de modules (CommonJS) différent des modules ECMAScript des navigateurs.
La convergence vers les modules ECMAScript est en cours. Il y a fort à parier qu’ils seront pris en charge nativement par Node dans une version ultérieure.
Nous verrons au chapitre 9 comment utiliser les modules Node dans les navigateurs.
9.4. L’interfaçage avec le système d’exploitation
Les fonctions ECMAScript spécifiques aux navigateurs sont liées
à la récupération d’informations (AJAX, fetch()),
à l’affichage (Canvas, WebGL, WebVR) ainsi qu’à la manipulation de
documents HTML.
Les fonctions ECMAScript fournies par les modules Node
sont liées à la gestion des ressources dont le système d’exploitation
se fait l’interface : fichiers (fs),
réseau (http, net, dns,
dgram), terminal (tty, readline)
et processus (process, child_process).
9.5. Node est un processus système
Le système d’exploitation crée un nouveau processus dès
qu’on exécute le programme node.
Il peut être de courte ou de longue durée, selon qu’il dure quelques secondes
ou un temps indéfini.
Le processus s’arrête en cas d’erreur, lorsqu’il n’y a plus d’opération à effectuer ou en cas d’interruption volontaire.
Le code ECMAScript exécuté dans un navigateur dépasse rarement la durée d’une session utilisateur, de quelques secondes à quelques heures. En cas de problème, un rafraîchissement de la page remet à zéro son état.
|
💬
|
Performances Utilisation des CPU
Un processus Node est mono CPU. Tous les autres processus système affectés à cette même CPU se partageront une quantité finie de puissance. Par exemple, si un processus Node partage la même CPU qu’une base de données et si une requête gourmande s’exécute, la rapidité de notre application en sera affectée. |
10. Options utiles pour démarrer Node
L’exécutable node accepte plusieurs options afin de personnaliser
son comportement et l’affichage des résultats.
|
💬
|
Documentation Exécutable node
La documentation de l’exécutable |
10.1. Afficher le résultat d’une expression, sans script
L’interpréteur Node sait interpréter du code qu’on lui donne
via l’option -p (pour print, c’est-à-dire afficher).
Il affiche le résultat de l’expression ou détaille la raison de l’erreur.
J’utilise cette forme d’interaction pour obtenir un résultat rapide, sans créer de nouveau fichier, par exemple, pour une opération mathématique :
node -p '2 + 2' 4
Toute expression ECMAScript valide est acceptée :
node -p '"abc".toLocaleUpperCase()' ABC
10.2. Précharger un module
L’option de démarrage --require charge le module indiqué avant le script Node.
node --require ./print-exit.js url/intro.js
Dans cet exemple, le module print-exit.js sera chargé
avant url/intro.js.
process.on('exit', (code) => {
const {filename} = process.mainModule;
console.log(`${filename} : arrêt avec le code ${code}`);
});Le chargement de ce module aura pour effet d’afficher un message avec le chemin du fichier chargé et le code de sortie.
On peut appeler l’option --require plusieurs fois, ou son raccourci `-r`.
Ce mécanisme fonctionne très bien avec des
modules npm conçus pour
rendre nos scripts compatibles avec les modules ECMAScript
ou pour simplifier les erreurs affichées
lors d’un plantage applicatif, entre autres.
10.3. Inspecter notre code avec Google Chrome
Node accepte deux options --inspect et --inspect-brk.
Elles exposent un protocole de débogage auquel on peut se connecter
avec le navigateur Chrome.
node --inspect-brk print-text.js texte --uppercase Debugger listening on ws://127.0.0.1:9229/ddd9bbfd-09ac-4426-a53e-c8abe4fc36da For help see https://nodejs.org/en/docs/inspector
Cette commande lance un de nos exemples de la section
sur le module process.
L’option --inspect-brk démarre l’inspecteur
et met aussitôt son exécution en pause.
Le logo de Node s’affiche dans les outils de développement de Chrome :
Un clic sur le logo Node ouvre une nouvelle fenêtre, outillée pour inspecter ce qui se passe dans notre script.
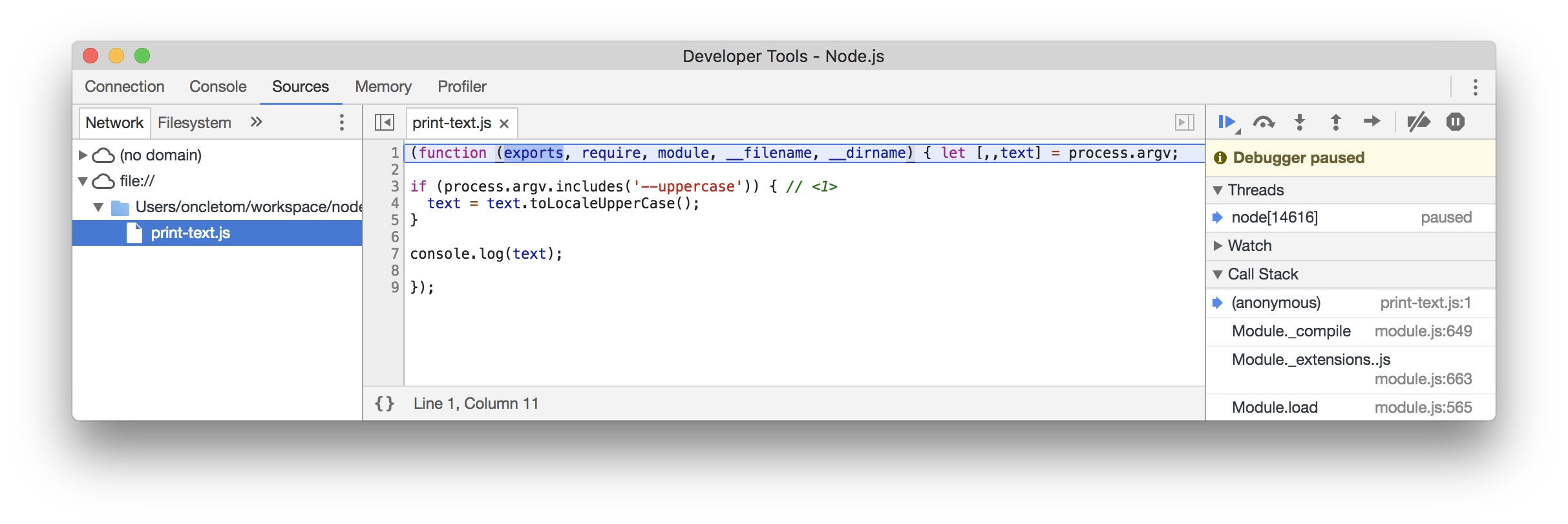
|
💡
|
Outils de développement Point d’arrêt
Un point d’arrêt se crée en cliquant sur le numéro de ligne souhaité. Le débogueur se mettra en pause à chaque fois que le chemin d’exécution de l’interpréteur atteindra cette ligne. La valeur des variables ECMAScript courantes s’affichent au survol de la souris ou en interagissant avec la console. |
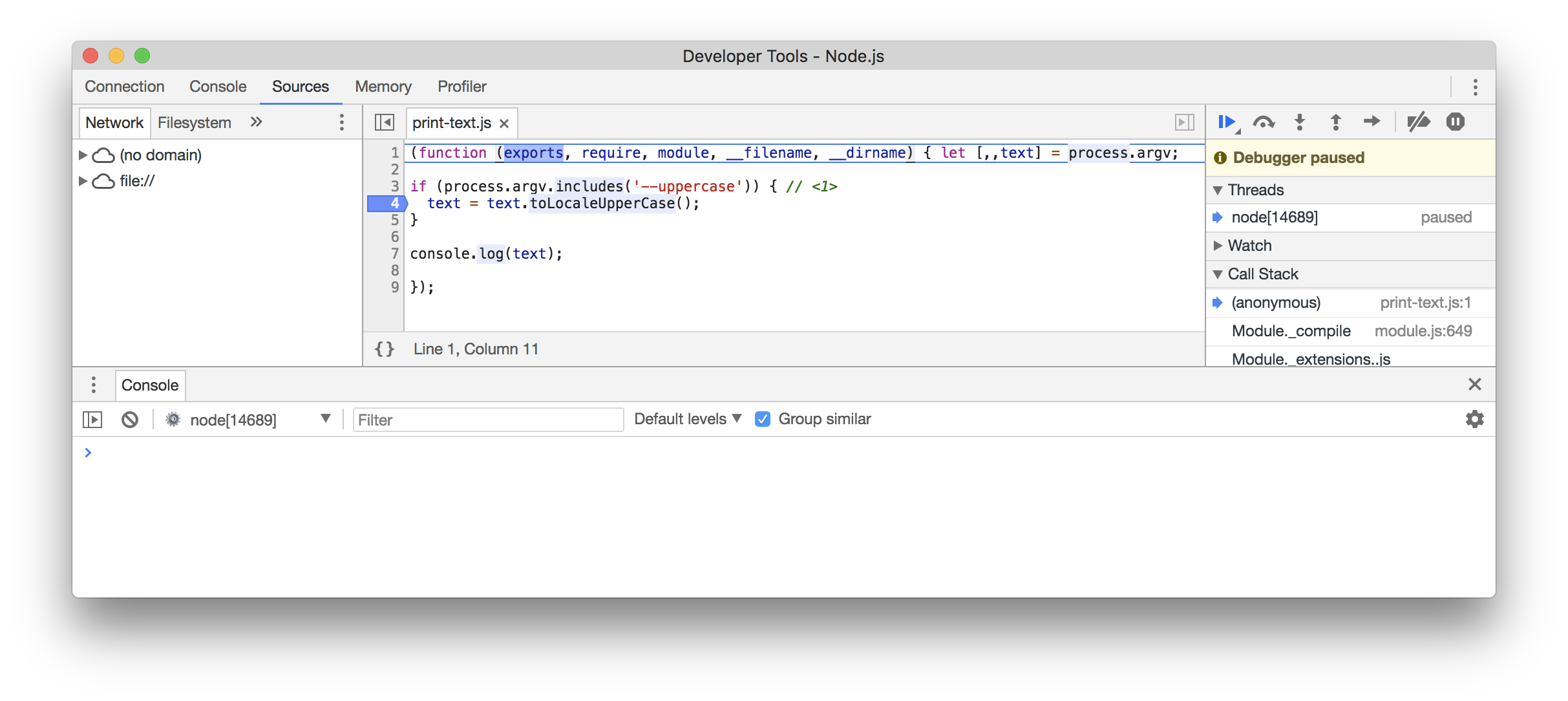
C’est le moment idéal pour placer un ou plusieurs point(s) d’arrêt.
Un clic sur le bouton ▶ met alors fin à la pause. Le script s’exécutera jusqu’à l’épuisement des instructions ou jusqu’au prochain point d’arrêt.
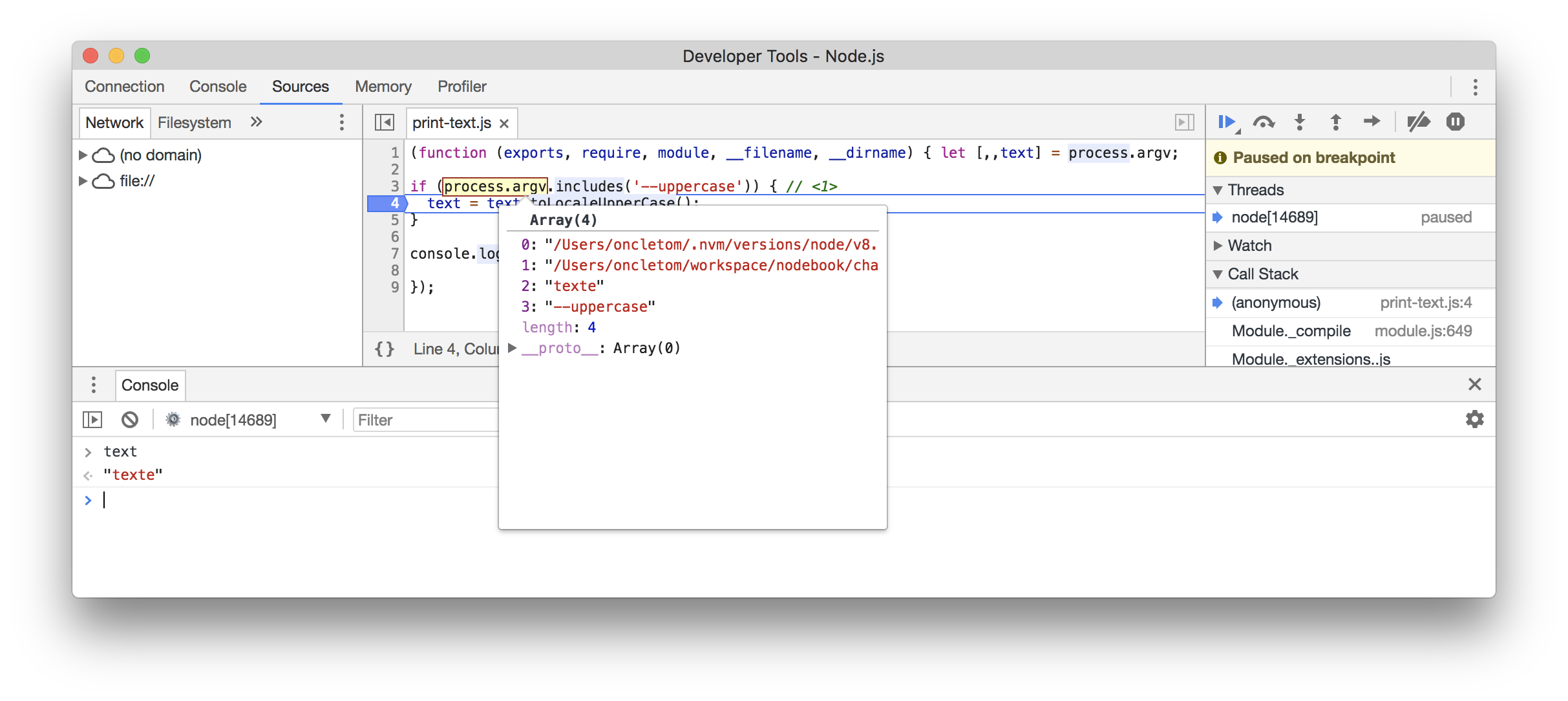
L’option --inspect est adaptée à des processus de longue durée,
comme un serveur HTTP.
L’option --inspect-brk est adaptée à des processus de courte durée et qui
se termineraient avant qu’on ait le temps de jeter un œil au contenu.
10.4. Ajuster les options de compatibilité et de traçabilité de V8
Node repose sur la machine virtuelle V8 pour interpréter nos instructions ECMAScript et en expose différentes options pour affiner son comportement en fonction de notre environnement.
L’intégralité des options de configuration de V8 s’affiche
avec l’option --v8-options :
node --v8-options
Il n’y a pas de meilleure configuration qui conviendrait à chacun de nos usages. Le mieux reste encore d’explorer les options possibles, les différents concepts et d’ajuster les valeurs offrant le meilleur rapport stabilité/performances.
--optimize_for_size-
Optimise le fonctionnement interne pour utiliser moins de mémoire, au détriment de la vitesse. Idéal pour l’exécution de scripts Node sur des environnements à faible mémoire, comme les Raspberry Pi.
--mem_old_space_limit-
Détermine la quantité de mémoire maximale qu’un processus Node pourra utiliser. Idéal pour le confiner sur des environnements à faible mémoire.
--gc_inverval-
Détermine le nombre de cycles entre chaque déclenchement du ramasse-miettes.
--expose_gc-
Expose les fonctions de manipulation du ramasse-miettes. Idéal si vous souhaitez contrôler finement l’optimisation de la mémoire.
--stack_trace_limit-
Change la limite du nombre de lignes affichées dans une trace d’erreur (10 par défaut).
--trace-deopt-
Signale les optimisations invalidées par V8. Les portions de code indiquées gagneraient à être retravaillées, pour rendre uniforme le type de variables passées en arguments par exemple.
--trace-gc-
Signale les moments où le ramasse-miettes se déclenche. On peut ainsi mieux en comprendre les raisons.
|
💬
|
Notion Ramasse-miettes (garbage collector)
Le ramasse-miettes est un mécanisme informatique qui libère les objets inutilisés de la mémoire. Il est déclenché de manière cyclique par la machine virtuelle V8. |
Les options préfixées par harmony activent la prise en charge
de fonctionnalités ECMAScript qui ne font pas encore partie du standard.
Elles sont encore au stade expérimental.
11. Conclusion
Les modules de base sont un élément différenciant entre Node et le langage ECMAScript. Ils nous interfacent avec le système d’exploitation pour naviguer dans les fichiers, ouvrir des connexions réseau et télécharger des fichiers distants. Bien les connaître nous aidera au quotidien.
L’organisation des modules CommonJS – voire des modules ECMAScript – est l’autre élément majeur de ce chapitre. Avec cela, nous rendons notre code modulaire, réutilisable et donc testable.
Toutes ces connaissances seront largement réutilisées dans les chapitres suivants.
Elles nous aideront à mieux choisir nos modules npm dans le chapitre 5,
à structurer une application web au chapitre 7, à créer de belles applications
en ligne de commande au chapitre 8 et même à partager du code entre Node
et les navigateurs au chapitre 9.